This white paper is for developers of Oracle applications who want to convert
their applications to Microsoft® SQL Server™ 2000. The tools, processes, and
techniques required for a successful conversion are described. Also highlighted are the
essential design points that allow you to create high-performance, high-concurrency SQL
Server-based applications.
The target audience can be new to SQL Server and its operation, but should have
a solid foundation in the Oracle RDBMS and general database concepts. The target audience
should have:
· A
strong background in Oracle RDBMS fundamentals.
·
General database management knowledge.
·
Familiarity with the Oracle SQL and PL/SQL languages.
·
Membership in the sysadmin fixed server role.
For clarity and ease of presentation, the reference
development and application platform is assumed to be the Microsoft Windows® 2000 operating systemand
SQL Server 2000. The Visigenic Software ODBC driver is used with Oracle, and the SQL Server
ODBC driver is used with SQL Server 2000. SQL Server 2000 includes an OLE DB driver for Oracle,
but that driver is not discussed extensively in this paper.
The application migration process can appear complicated. There are many
architectural differences between each RDBMS. The words and terminology used to describe Oracle
architecture often have completely different meanings in Microsoft SQL Server. Additionally,
both Oracle and SQL Server have made many proprietary extensions to the SQL-92 standard.
From an application developer's perspective, Oracle and SQL Server manage data
in similar ways. The internal differences between Oracle and SQL Server are significant, but if
managed properly, have minimal impact on a migrated application.
The most significant migration issue that confronts the developer is the
implementation of the SQL-92 SQL language standard and the extensions that each RDBMS has to
offer. Some developers use only standard SQL language statements, preferring to keep their
program code as generic as possible. Generally, this means restricting program code to the
entry-level SQL-92 standard, which is implemented consistently across many database products,
including Oracle and SQL Server.
This approach can produce unneeded complexity in the program code and can
substantially affect program performance. For example, Oracle's DECODE function is a
nonstandard SQL extension specific to Oracle. The CASE expression in SQL Server is a SQL-92
extension beyond entry level and is not implemented in all database products.
Both the Oracle DECODE and the SQL Server CASE expressions can perform
sophisticated conditional evaluation from within a query. The alternative to not using these
functions is to perform the function programmatically, which might require that substantially
more data be retrieved from the RDBMS.
Also, procedural extensions to the SQL language can cause difficulties. The
Oracle PL/SQL and SQL Server Transact‑SQL languages are similar in function, but
different in syntax. There is no exact symmetry between each RDBMS and its procedural
extensions. Consequently, you might decide not to use stored programs such as procedures and
triggers. This is unfortunate because they can offer substantial performance and security
benefits that cannot be duplicated in any other way.
The use of proprietary development interfaces introduces additional issues. The
conversion of a program using the Oracle OCI (Oracle Call Interface) often requires a
significant investment in resources. When developing an application that may use multiple
RDBMSs, consider using the Open Database Connectivity (ODBC) interface.
ODBC is designed to work with numerous database management systems. ODBC
provides a consistent application programming interface (API) that works with different
databases through the services of a database-specific driver.
A consistent API means that the functions a program calls to make a connection,
execute a command, and retrieve results are identical whether the program is talking to Oracle
or SQL Server.
ODBC also defines a standardized call-level interface and uses standard escape
sequences to specify SQL functions that perform common tasks but have different syntax in
different databases. The ODBC drivers can automatically convert this ODBC syntax to either
Oracle-native or SQL Server-native SQL syntax without requiring the revision of any program
code. In some situations, the best approach is to write one program and allow ODBC to perform
the conversion process at run time.
ODBC by itself does not provide complete database independence, full
functionality, and high performance from all databases. Different databases and third-party
vendors offer varying levels of ODBC support. Some drivers implement only core API functions
mapped on top of other interface libraries. Other drivers, such as the SQL Server ODBC driver,
offer full Level 2 support in a native, high-performance driver.
If a program uses only the core ODBC API, it will likely forego features and
performance capabilities with some databases. Furthermore, not all native SQL extensions can be
represented in ODBC escape sequences (such as Oracle DECODE and SQL Server CASE
expressions).
Additionally, it is common practice to write SQL statements to take advantage
of the database's optimizer. The techniques and methods that enhance performance within Oracle
are not necessarily optimal within SQL Server 2000. The ODBC interface cannot translate
techniques from one RDBMS to another.
ODBC does not prevent an application from using database-specific features and
tuning for performance, but the application needs some database-specific sections of code. ODBC
makes it easy to keep the program structure and the majority of the program code consistent
across multiple databases.
SQL Server 2000 takes advantage of OLE DB within the components of SQL Server
itself. Additionally, application developers should consider OLE DB for new development with
SQL Server 2000. Microsoft includes an OLE DB provider for Oracle 8 with SQL Server 2000.
OLE DB is an open specification designed to build on the features of ODBC. ODBC
was created to access relational databases, and OLE DB is designed to access relational and
nonrelational information sources, such as mainframe ISAM/VSAM and hierarchical databases,
e-mail and file system stores, text, graphical and geographical data, and custom business
objects.
OLE DB defines a collection of COM interfaces that encapsulate various database
management system services and allows the creation of software components that implement such
services. OLE DB components consist of data providers (that contain and expose data), data
consumers (that use data), and service components (that process and transport data, for
example, query processors and cursor engines).
OLE DB interfaces are designed to help components integrate smoothly so that
OLE DB component vendors can bring high quality OLE DB components to the market quickly. In
addition, OLE DB includes a bridge to ODBC to allow continued support for the broad range of
ODBC relational database drivers available today.
To assist you in implementing a systematic migration from Oracle to SQL Server,
each section includes an overview of the relevant differences between Oracle databases and
Microsoft SQL Server 2000. The paper also includes conversion considerations, SQL Server 2000
advantages, and multiple examples.
Where appropriate, the paper provides references to external sources that
describe the topic in more detail.
To start a successful migration, you should understand the basic architecture
and terminology associated with SQL Server 2000.
In Oracle, a database refers to the entire Oracle RDBMS environment and
includes these components:
·
Oracle database processes and buffers (instance).
·
SYSTEM tablespace containing one centralized system catalog, which is made up of one or more
datafiles.
·
Other tablespaces as defined by the DBA (optional), each made up of one or more datafiles.
·
Two or more online Redo Logs.
·
Archived Redo Logs (optional).
·
Miscellaneous other files (control file, Init.ora, config.ora, and so on).
A SQL Server database provides a logical separation of data, applications, and
security mechanisms. A SQL Server installation (an instance) can support multiple databases.
Applications built using SQL Server can use databases to logically divide business
functionality. There can be multiple instances of SQL Server on a single computer. Each
instance of SQL Server can have multiple databases.
Each SQL Server database can support filegroups,
which provide the ability to distribute the placement of the data physically. A SQL Server
filegroup categorizes the operating-system files containing data from a single SQL Server
database to simplify database administration tasks, such as backing up. A filegroup belongs to
a single is a property of a SQL Server database and cannot contain the operating-system files
of more than one database, although a single database can contain more than one filegroup.
Filegroups can be defined during database creation or added after the database has been
created.
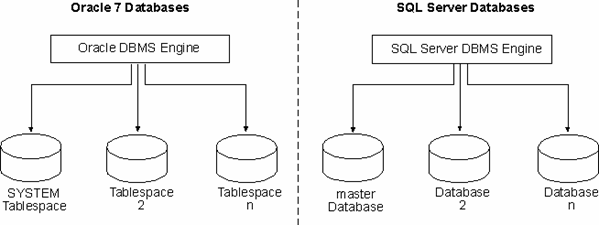
SQL Server also installs the following databases by default:
·
The model database is a template for all newly created user
databases.
·
The tempdb database is similar to an Oracle temporary tablespace in
that it is used for temporary working storage and sort operations. Unlike the Oracle temporary
tablespace, SQL Server users can create temporary tables that are automatically dropped when
the user logs off.
·
The msdb database supports the SQL Server Agent and its scheduled
jobs, alerts, and replication information.
·
The pubs and Northwind databases are
provided as sample databases for training and examples in the documentation.
For more information about the default databases, see SQL Server 2000 Books
Online.
Each Oracle database runs on one centralized system catalog, or data
dictionary, which resides in the SYSTEM tablespace. Each SQL Server 2000 database maintains its
own system catalog, which contains information about:
·
Database objects (tables, indexes, stored procedures, views, triggers, and so on).
·
Constraints.
·
Users and permissions.
·
User-defined data types.
·
Replication definitions.
·
Files used by the database.
SQL Server also contains a centralized system catalog in the master database, which contains system catalogs as well as some information about
the individual databases:
·
Database names and the primary file location for each database.
·
SQL Server login accounts.
·
System messages.
·
Database configuration values.
·
Remote and/or linked servers.
·
Current activity information.
·
System stored procedures.
Similar to the SYSTEM tablespace in Oracle, the SQL Server master database must be available to access any other database. It is important
to protect against failures by backing up the master database after
any significant changes are made in the database. Database administrators can also mirror the
files that make up the master database.
For information about a list of the system tables contained in the master and all other databases, see "System Tables" in SQL Server 2000 Books
Online.
The Oracle RDBMS is comprised of tablespaces, which in turn are comprised of
datafiles. Tablespace datafiles are formatted into internal units termed blocks. The block size is set by the DBA when the Oracle database is first
created. When an object is created in an Oracle tablespace, the user can specify its space in
units called extents (initial extent, next extent, min extents, and
max extents). If an extent size is not defined explicitly, a default extent is created. An
Oracle extent varies in size and must contain a chain of at least five contiguous blocks.
SQL Server uses filegroups at the database level to control the physical
placement of tables and indexes. Filegroups are logical containers of one or more files, and
data contained within a filegroup is proportionally filled across all files belonging to the
filegroup.
If additional filegroups are not defined and used, database objects are placed
in the primary filegroup that is implicitly defined during the creation of a database.
Filegroups allow you to:
·
Distribute large tables across multiple files to improve I/O throughput.
·
Store indexes on different files than their respective tables, again to improve I/O throughput
and disk concurrency.
·
Store text, ntext, and image columns (large objects) on separate files from the table.
·
Place database objects on specific disk spindles.
·
Back up and restore individual tables or sets of tables within a filegroup.
SQL Server formats files into internal units called pages. The page size is fixed at 8192 bytes (8 KB). Pages are organized into
extents that are fixed in size at 8 contiguous pages (64 KB). When a table or index is created
in a SQL Server database, it is automatically allocated one page within an extent. As the table
or index grows, it is automatically allocated space by SQL Server. This allows for more
efficient storage of smaller tables and indexes when compared to allocating an entire extent as
in Oracle. For more information, see "Physical Database Architecture" in SQL Server 2000 Books
Online.
Oracle-type segments are not needed for most SQL Server installations. Instead,
SQL Server can distribute, or stripe, data more efficiently with hardware-based RAID or with
software-based RAID available through the Windows Disk Management utility or from third
parties. With RAID, you can set up striped volumes (stripe sets in Windows NT 4.0) consisting
of multiple disk drives that appear as one logical drive. If database files are created on this
striped volume, the disk subsystem assumes responsibility for distributing I/O load across
multiple disks. It is recommended that administrators spread out the data over multiple
physical disks using RAID.
The recommended RAID configuration for SQL Server is RAID 1 (mirroring) or RAID
5 (stripe sets with an extra parity drive, for redundancy). RAID 10 (mirroring of striped sets
with parity) is also recommended, but is much more expensive than the first two options. Stripe
sets work very well to spread out the usually random I/O done on database files.
If RAID is not an option, filegroups are an attractive alternative and provide
some of the same benefits available with RAID. Additionally, for very large databases that
might span multiple physical RAID arrays, filegroups may be an attractive way to further
distribute your I/O across multiple RAID arrays in a controlled fashion.
Transaction log files must be optimized for sequential I/O and must be secured
against a single point of failure. Accordingly, RAID 1 (mirroring) is recommended for
transaction logs. When migrating, the size of this drive should be at least as large as the sum
of the size of the Oracle online redo logs and the Oracle rollback segment tablespace(s).
Create one or more log files that take up all the space defined on the logical drive. Unlike
data stored in filegroups, transaction log entries are always written sequentially and are not
proportionally filled.
For more information about RAID, see SQL Server 2000 Books Online, the
Microsoft Windows 2000 documentation, and the Microsoft Windows 2000
Resource Kit.
The Oracle RDBMS performs automatic recovery each time it is started. It
verifies that the contents of the tablespace files are coordinated with the contents of the
online redo log files. If they are not, Oracle applies the contents of the online redo log
files to the tablespace files (roll forward), and then removes any uncommitted transactions
that are found in the rollback segments (roll back). If Oracle cannot obtain the information it
requires from the online redo log files, it consults the archived redo log
files.
SQL Server 2000 also performs automatic data recovery by checking each database
in the system each time it is started. It first checks the master
database and then launches threads to recover all of the other databases in the system. For
each SQL Server database, the automatic recovery mechanism checks the transaction log. If the
transaction log contains any uncommitted transactions, the transactions are rolled back. The
recovery mechanism then checks the transaction log for committed transactions that have not yet
been written out to the database. If it finds any, it performs those transactions again,
rolling forward.
Each SQL Server transaction log has the combined functionality of an Oracle
rollback segment and an Oracle online redo log. Each database has its own transaction log that
records all changes to the database and is shared by all users of that database. When a
transaction begins and a data modification occurs, a BEGIN TRANSACTION event (as well as the
modification event) is recorded in the log. This event is used during automatic recovery to
determine the starting point of a transaction. As each data modification statement is received,
the changes are written to the transaction log prior to being written to the database itself.
For more information, see "Transactions, Locking, and Concurrency" later in this paper.
SQL Server has an automatic checkpoint mechanism that ensures completed
transactions are regularly written from the SQL Server disk cache to the transaction log file.
A checkpoint writes any cached page that has been modified since the last checkpoint to the
database. Checkpointing these cached pages, known as dirty pages, onto the database, ensures
that all completed transactions are written out to disk. This process shortens the time that it
takes to recover from a system failure, such as a power outage. This setting can be changed by
modifying the recovery interval setting by using SQL Server Enterprise Manager or with
Transact‑SQL (sp_configure system stored procedure).
Microsoft SQL Server offers several options for backing up data:
Full database backup
A database backup makes a copy of the full database. Not all pages are
copied to the backup set, only those actually containing data. Both data pages and transaction
log pages are copied to the backup set.
A database backup set is used to re-create the database as it was at the
time the BACKUP statement completed. If only database backups exist for a database, it can be
recovered only to the time of the last database backup taken before the failure of the server
or database. To make a full database backup, use the BACKUP DATABASE statement or the Create
Database Backup Wizard.
Differential backup
After a full database backup, regularly back up just the changed data and
index pages using the BACKUP DATABASE WITH DIFFERENTIAL statement or the Create Database Backup
Wizard.
Transaction log backup
Transaction logs in Microsoft SQL Server are associated with individual
databases. The transaction log fills until it is backed up or truncated. The default
configuration of SQL Server 2000 is that the transaction log grows automatically until it uses
all available disk space or it meets its maximum configured size. When a transaction log gets
too full, it can create an error and prevent further data modifications until it is backed up
or truncated. Other databases are not affected. Transaction logs can be backed up using the
BACKUP LOG statement or the Create Database Backup Wizard.
File backup, filegroup backup
A file or filegroup backup copies one or more files of a specified
database, allowing a database to be backed up in smaller units: at the file or filegroup level.
For more information, see SQL Server 2000 Books Online.
Backups can be performed while the database is in use, allowing backups to be
made of systems that must run continually. The backup processing and internal data structures
of SQL Server maximize their rate of data transfer with minimal effect on transaction
throughput.
Both Oracle and SQL Server require a specific format for backup files. In SQL
Server, these files, called backup devices, are created using SQL Server Enterprise Manager,
the Transact‑SQL sp_addumpdevice stored procedure, or the
equivalent SQL-DMO command.
Although backups can be performed manually, it is recommended that you use SQL
Server Enterprise Manager and/or the Database Maintenance Plan Wizard to schedule periodic
backups, or backups based on database activity.
A database can be restored to a certain point in time by applying transaction
log backups and/or differential backups to a full database backup (device). A database restore
overwrites the data with the information contained in the backups. Restores can be performed
using SQL Server Enterprise Manager, Transact‑SQL (RESTORE DATABASE), or SQL-DMO.
Just as you can turn off the Oracle archiver to override automatic backups, in
Microsoft SQL Server, members of the db_owner fixed database role can
force the transaction log to erase its contents every time a checkpoint occurs. This can be
accomplished by using SQL Server Enterprise Manager (set the recovery model to Simple), Transact‑SQL (ALTER DATABASE), or SQL-DMO.
Oracle SQL*Net supports networked connections between Oracle database servers
and their clients. It communicates with the Transparent Network Substrate (TNS) data stream
protocol, and allows users to run many different network protocols without writing specialized
code.
With SQL Server, Net-Libraries (network libraries) support the networked
connections between the clients and the server by using the Tabular Data Stream (TDS) protocol.
They enable simultaneous connections from clients running Named Pipes, TCP/IP Sockets, or other
Inter-Process Communication (IPC) mechanisms. The SQL Server 2000 CD-ROM includes all client
Net-Libraries so that there is no need to acquire them separately.
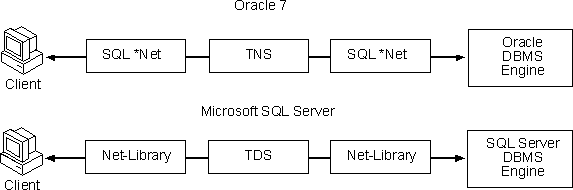
SQL Server Net-Library options can be changed after installation. The Client
Network utility configures the default Net‑Library and server connection information for
a client running the Windows 2000, Windows NT 4.0, Windows 95, Windows 98, or Windows
Millennium operating systems. All ODBC client applications use the same default
Net‑Library and server connection information, unless it is changed during ODBC data
source setup or explicitly coded in the ODBC connection string. For more information about
Net-Libraries, see SQL Server 2000 Books Online.
To migrate your Oracle applications to SQL Server 2000 adequately, you must
understand how SQL Server implements database security and roles.
Microsoft Windows 2000 allows users to encrypt files using the Encrypting File
System (EFS). SQL Server 2000 can use EFS. The database files can be encrypted, preventing
other users from moving, copying, or viewing their contents. This encryption is done on the
operating-system level, not the logical database level. After SQL Server opens the encrypted
file, the data within the file appears as unencrypted.
SQL Server 2000 supports the use of the Secure Sockets Layer (SSL) to encrypt
network communications between itself and clients. This encryption applies to all
inter-computer protocols supported by SQL Server 2000, and is either 40-bit or 128-bit
depending on the version of the Windows operating system on which SQL Server is running. For
more information, see "Net-Library Encryption" in SQL Server 2000 Books
Online.
A login account allows a user to access SQL Server data or administrative
options. A login ID only enables you to connect to an instance of SQL Server. Permissions
within specific databases are controlled by user accounts. The database administrator maps your
login account to a user account in any database you are authorized to access.
A login account allows a user to administer or access data in an instance of
SQL Server 2000. SQL Server 2000 uses two different methods to authenticate logins:
·
Windows Authentication
A DBA specifies which Windows login accounts can be used to connect to
an instance of SQL Server 2000. Users logged in to Windows using these accounts can connect to
SQL Server 2000 without having to specify a separate database login and password. When using
Windows Authentication, SQL Server 2000 uses the security mechanisms of Windows NT 4.0 or
Windows 2000 to validate login connections, and relies on a user's Windows security
credentials. Users do not need to enter login IDs or passwords for SQL Server 2000 because
their login information is taken directly from the trusted network connection. This functions
like the IDENTIFIED EXTERNALLY option associated with Oracle user accounts.
·
SQL Server Authentication
A DBA defines a separate database login account. A user must specify
this login account and its password when they attempt to connect to SQL Server 2000. The
database login is not related to the user's Windows login. This functions like the IDENTIFIED
BY PASSWORD option associated with Oracle user accounts.
Each instance of SQL Server 2000 is run in one of two authentication modes:
·
Windows Authentication Mode (known as integrated security in earlier versions of SQL Server).
In this mode, SQL Server 2000 allows only connections that use Windows Authentication.
·
Mixed Mode. In this mode, connections can be made using either Windows Authentication or SQL
Server Authentication.
For more information about these security mechanisms, see SQL Server 2000 Books
Online.
SQL Server and Oracle use permissions to enforce database security. SQL Server
statement-level permissions are used to restrict the ability to create new database objects
(similar to the Oracle system-level permissions).
SQL Server also offers object-level permissions. As in Oracle, object-level
ownership is assigned to the creator of the object and cannot be transferred. Object-level
permissions must be granted to other database users before they can access the object. Members
of the sysadmin fixed server role, db_owner
fixed database role, or db_securityadmin fixed database role can also
grant permissions on one user's objects to other users.
SQL Server statement-level and object-level permissions can be granted directly
to database user accounts. However, it is often easier to administer permissions to database
roles. SQL Server roles are used for granting and revoking privileges to groups of database
users (much like Oracle roles). Roles are database objects associated with a specific database.
There are a few specific fixed server roles associated with each installation, which work
across databases. An example of a fixed server role is sysadmin.
Windows groups can also be added as SQL Server logins, as well as database users. Permissions
can be granted to a Windows group or a Windows user.
The default role public is always found in every
database and cannot be removed. The public role functions much like
the PUBLIC account in Oracle. Each database user is always a member of the public role. A database user can be a member of any number of roles in addition
to the public role. A Windows user or group can also be a member of
any number of roles, and is also always in the public role.
In Microsoft SQL Server, a user login account must be authorized to use a
database and its objects. One of the following methods can be used by a login account to access
a database:
·
The login account can be specified as a database user.
·
The login account can use a guest account in the database.
· A
Windows group login can be mapped to a database role. Individual Windows accounts that are
members of that group can then connect to the database.
Members of the db_owner or db_accessadmin roles, or the sysadmin fixed server
role, create the database user account roles. An account can include several parameters: the
SQL Server login ID, database user name (optional), and up to one role name (optional). The
database user name does not have to be the same as the user's login ID. If a database user name
is not provided, the user's login ID and database user name are identical. If a role name is
not provided, the database user is only a member of the public role.
After creating the database user, the user can be assigned to as many roles as
necessary.
Members of the db_owner or db_accessadmin roles can also create a guestaccount.
The guest account allows any valid SQL Server login account to access
a database even without a database user account. By default, the guest account inherits any privileges that have been assigned to the public role; however, these privileges can be changed to be greater or less than
that of the public role.
A Windows user account or group account can be granted access to a database,
just as a SQL Server login can. When a Windows user who is a member in a group connects to the
database, the user receives the permissions assigned to the Windows group. If a member of more
than one Windows group that has been granted access to the database connects to the database,
the user receives the combined rights of all of the groups to which he or she belongs.
Members of the SQL Server sysadmin fixed server role
have similar permissions to that of an Oracle DBA. In SQL Server, the sa SQL Server Authentication login account is a member of this role by default,
as are members of the local Administrators group if SQL Server is
installed on a computer running Windows 2000. A member of the sysadmin role can add or remove Windows users and groups, as well as SQL Server
logins. Members of this role typically have the following responsibilities:
·
Installing SQL Server.
·
Configuring servers and clients.
·
Creating databases.*
·
Establishing login rights and user permissions.*
·
Transferring data in and out of SQL Server databases.*
·
Backing up and restoring databases.*
·
Implementing and maintaining replication.
·
Scheduling unattended operations.*
·
Monitoring and tuning SQL Server performance.*
·
Diagnosing system problems.
*These items can be delegated to other security roles or users.
A member of the sysadmin fixed server role can access
any database and all of the objects (including data) on a particular instance of SQL Server.
Similar to an Oracle DBA, there are several commands and system procedures that only members of
the sysadmin role can issue.
Although a SQL Server database is similar to an Oracle tablespace in use, it is
administered differently. Each SQL Server database is a self-contained administrative domain.
Each database is assigned a database owner (dbo). This user is always
a member of the db_owner fixed database role. Other users can also be
members of the db_owner role. Any user who is a member of this role
has the ability to manage the administrative tasks related to her database (unlike Oracle, in
which one DBA manages the administrative tasks for all tablespaces). These tasks include:
·
Managing database access.
·
Changing database options (read-only, single user, and so on).
·
Backing up and restoring the database contents.
·
Granting and revoking database permissions.
·
Creating and dropping database objects.
Members of the db_owner role have permissions to do
anything within their database. Most rights assigned to this role are separated into several
fixed database roles, or can be granted to database users. It is not necessary to have
sysadmin server-wide privileges to have db_owner privileges in a database.
Oracle database objects (tables, views, and indexes) can be migrated to SQL
Server easily because each RDBMS closely follows the SQL-92 standard that regards object
definitions.
For more information, see "Logical Database Components" in SQL Server 2000
Books Online.
Converting Oracle SQL table, index, and view definitions to SQL Server table,
index, and view definitions requires relatively simple syntax changes. This table shows some
differences in database objects between Oracle and SQL Server.
|
Category
|
Microsoft SQL Server
|
Oracle
|
|
Number of columns
|
1,024
|
1,000
|
|
Row size
|
8,060 bytes, including 16 bytes to point to each text or image column
|
Unlimited (only one long or long raw allowed per row)
|
|
Maximum number of rows
|
Unlimited
|
Unlimited
|
|
Blob type storage
|
16-byte pointer stored with row. Data stored on other data pages
|
One long or long raw per table, must be at end of row, data stored on
same block(s) with row
|
|
Clustered table indexes
|
1 per table
|
1 per table (index-organized tables)
|
|
Nonclustered table indexes
|
249 per table
|
Unlimited
|
|
Maximum number of columns in single index
|
16
|
32
|
|
Maximum length of column values within of an index
|
900 bytes
|
40% of block
|
|
Table naming convention
|
[[[Server.]database.]owner.]
table_name
|
[schema.]table_name
|
|
View naming convention
|
[[[Server.]database.]owner.]
table_name
|
[schema.]table_name
|
|
Index naming convention
|
[[[Server.]database.]owner.]
table_name
|
[schema.]table_name
|
It is assumed that you are starting with an Oracle SQL script or program that
is used to create your database objects. Copy this script or program and make the following
modifications. Each change is discussed throughout the rest of this section.
1. Ensure database object
identifiers comply to Microsoft SQL Server naming conventions. You may need to change only the
names of indexes.
2. Consider the data storage
parameters your SQL Server database will require. If you are using RAID, no storage parameters
are required.
3. Modify Oracle constraint
definitions to work in SQL Server. If tables cross databases, use triggers to enforce foreign
key relationships.
4. Modify the CREATE INDEX
statements to take advantage of clustered indexes.
5. Use Data Transformation
Services (DTS) to create new CREATE TABLE statements. Review the statements, taking note of how
Oracle data types are mapped to SQL Server data types.
6. Remove any CREATE SEQUENCE
statements. Replace the use of sequences with IDENTITY or uniqueidentifier columns in CREATE TABLE or ALTER TABLE statements.
7. Modify CREATE VIEW
statements if necessary.
8. Remove any reference to
synonyms.
9. Evaluate the use of SQL
Server temporary tables and their usefulness if your application creates tables for short
periods of time and then drops them.
10. Change any
Oracle CREATE TABLE…AS SELECT commands to SQL Server SELECT…INTO statements.
11. Evaluate
the potential use of user-defined rules, data types, and defaults.
The following table compares how Oracle and SQL Server handle object
identifiers. In most cases, you do not need to change the names of objects when migrating to
SQL Server.
|
Oracle
|
Microsoft SQL Server
|
|
1-30 characters in length.
Database names: up to 8 characters long
Database link names: up to 128 characters long
|
1-128 Unicode characters in length
Temporary table names: up to 116 characters
|
|
Identifier names must begin with an alphabetic character and contain
alphanumeric characters, or the characters _, $, and #.
|
Identifier names can begin with an alphanumeric character, or an _, and
can contain virtually any character.
If the identifier begins with a space, or contains characters other than _, @, #, or $,
you must use [ ] (delimiters) around the identifier name.
If an object begins with:
@ it is a local variable.
# it is a local temporary object.
## it is a global temporary object.
|
|
Tablespace names must be unique.
|
Database names must be unique.
|
|
Identifier names must be unique within user accounts (schemas).
|
Identifier names must be unique within database user accounts.
|
|
Column names must be unique within tables and views.
|
Column names must be unique within tables and views.
|
|
Index names must be unique within a user's schema.
|
Index names must be unique within database table names.
|
When accessing tables that exist in your Oracle user account, the table can be
selected simply by its unqualified name. Accessing tables in other Oracle schemas requires that
the schema name be prefixed to the table name with a single period (.). Oracle synonyms can
provide additional location transparency.
SQL Server uses a different convention when it references tables. Because one
SQL Server login account can create a table by the same name in multiple databases, the
following convention is used to access tables and views: [[database_name.]owner_name.]table_name.
|
Accessing a table in…
|
Oracle
|
Microsoft SQL Server
|
|
Your user account
|
SELECT * FROM STUDENT
|
SELECT * FROM USER_DB.STUDENT_ADMIN.STUDENT
|
|
Other schema
|
SELECT * FROM STUDENT_ADMIN.STUDENT
|
SELECT * FROM OTHER_DB.STUDENT_ADMIN.STUDENT
|
Here are guidelines for naming SQL Server tables and views:
·
Using the database name and user name is optional. When a table is referenced only by name (for
example, STUDENT), SQL Server searches for that table in the current
user's account in the current database. If it does not find one, it looks for an object of the
same name owned by the reserved user name of dbo in the database.
Table names must be unique within a user's account within a database.
·
The same SQL Server login account can own tables with the same name in multiple databases. For
example, the ENDUSER1 account owns the following database objects:
USER_DB.ENDUSER1.STUDENT and OTHER_DB.ENDUSER1.STUDENT. The qualifier is the database username, not the SQL
Server login name, because they do not have to be the same.
·
At the same time, other users in these databases may own objects by the same name:
· USER_DB.DBO.STUDENT
· USER_DB.DEPT_ADMIN.STUDENT
· USER_DB.STUDENT_ADMIN.STUDENT
· OTHER_DB.DBO.STUDENT
Therefore, it is recommended that you include the owner name as part of the
reference to a database object. If the application has multiple databases, it is recommended
that the database name also is included as part of the reference. If the query spans multiple
servers, include the server name.
·
Every connection to SQL Server has a current database context, set at login time to the
account's default database or set on demand with the USE statement. For example, assume the
following scenario:
A user, using the ENDUSER1 account, is logged
in to the USER_DB database. The user requests the STUDENT table. SQL Server searches for the table ENDUSER1.STUDENT. If the table is found, SQL Server performs the requested
database operation on USER_DB.ENDUSER1.STUDENT. If the table is not
owned by the ENDUSER1 database account,, SQL Server searches for
USER_DB.DBO.STUDENT ownership by the dbo user for that database. If the table is still not found, SQL Server returns
an error message indicating the table does not exist.
·
If another user, for example DEPT_ADMIN, owns the table, the table
name must be prefixed with the database user's name (DEPT_ADMIN.STUDENT). Otherwise, the database name defaults to the database that
is currently in context.
·
If the referenced table exists in another database, the database name must be used as part of
the reference. For example, to access the STUDENT table owned by
ENDUSER1 in the OTHERDB database, use
OTHER_DB.ENDUSER1.STUDENT.
The object's owner can be omitted by separating the database and table name by
two periods. For example, if an application references STUDENT_DB..STUDENT, SQL Server searches as follows:
1.
STUDENT_DB.current_user.STUDENT
2. STUDENT_DB.DBO.STUDENT
If the application uses only a single database at a time, omitting the database
name from an object reference makes it easy to use the application with another database. All
object references implicitly access the database that is currently being used. This is useful
when you want to maintain a test database and a production database on the same
server.
Because Oracle and SQL Server support SQL-92 entry-level conventions for
identifying RDBMS objects, the CREATE TABLE syntax is similar.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE TABLE
[schema.]table_name
(
{col_name column_properties
[default_expression] [constraint
[constraint
[...constraint]]]| [[,] constraint]}
[[,] {next_col_name | next_constraint}...]
)
[Oracle Specific Data Storage Parameters]
|
CREATE TABLE [server.][database.][owner.] table_name
(
{col_name column_properties[constraint
[constraint [...constraint]]]|
[[,] constraint]}
[[,] {next_col_name | next_constraint}...]
)
[ON file group_name]
|
Oracle database object names are not case-sensitive. In SQL Server, database
object names can be case-sensitive, depending on the installation options selected.
When SQL Server is first set up, the default sort order is dictionary order,
case-insensitive. (This can be configured differently using SQL Server Setup.) Because Oracle
object names are always unique, you should not have any problems migrating the database objects
to SQL Server. It is recommended that all table and column names in both Oracle and SQL Server
be uppercase to avoid problems if a user installs on a case-sensitive SQL Server.
With Microsoft SQL Server, using RAID usually simplifies the placement of
database objects. A SQL Server clustered index is integrated into the structure of the table,
like an Oracle index-organized table.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE TABLE DEPT_ADMIN.DEPT(
DEPTVARCHAR(4) NOT NULL,
DNAMEVARCHAR(30) NOT NULL,
CONSTRAINT dept_pk PRIMARY KEY (dept) ,
CONSTRAINT dept_dname_unique UNIQUE(dname)
)
ORGANIZATION INDEX
|
CREATE TABLE
USER_DB.DEPT_ADMIN.DEPT (
DEPT
VARCHAR(4) NOT NULL,
DNAMEVARCHAR(30) NOT NULL,
CONSTRAINT DEPT_DEPT_PK
PRIMARY KEY CLUSTERED (DEPT),
CONSTRAINT DEPT_DNAME_UNIQUE
UNIQUE NONCLUSTERED (DNAME)
)
|
Using Oracle, a table can be created with any valid SELECT command. Microsoft
SQL Server provides the same functionality with different syntax.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE TABLE STUDENTBACKUP AS SELECT * FROM STUDENT
|
SELECT * INTO STUDENTBACKUP FROM STUDENT
|
The SELECT …INTO statement creates a new table and populates it with the
results of the SELECT statement. Referential integrity definitions are not transferred to the
new table. If the database recovery mode is set to FULL, the SELECT …INTO statement is
logged in the transaction log and a point-in-time recovery can take place.
For more information about database recovery models, see "Selecting a Recovery
Model" in SQL Server 2000 Books Online.
The syntax used to create views in SQL Server is similar to that of Oracle.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE [OR REPLACE] [FORCE |
NOFORCE] VIEW [schema.]view_name
[(column_name [, column_name]...)]
AS select_statement
[WITH CHECK OPTION [CONSTRAINT name]]
[WITH READ ONLY]
|
CREATE VIEW [owner.]view_name
[(column_name [, column_name]...)]
[WITH ENCRYPTION]
AS select_statement [WITH CHECK OPTION]
|
SQL Server views require that the tables exist and that the view owner has
privileges to access the requested tables(s) specified in the SELECT statement (similar to the
Oracle FORCE option).
By default, data modification statements on views are not checked to determine
whether the rows affected are within the scope of the view. To check all modifications, use the
WITH CHECK OPTION. The primary difference between the WITH CHECK OPTION is that Oracle defines
it as a constraint, and SQL Server does not. Otherwise, it functions the same in both.
Oracle provides a WITH READ ONLY option when defining views. SQL Server-based
applications can achieve the same result by granting only SELECT permission to the users of the
view.
Both SQL Server and Oracle views support derived columns, using arithmetic
expressions, functions, and constant expressions. Some of the specific SQL Server differences
are:
·
Data modification statements (INSERT or UPDATE) are allowed on multitable views if the data
modification statement affects only one base table. Data modification statements cannot be used
on more than one table in a single statement.
·
READTEXT or WRITETEXT cannot be used on text or image columns in views.
·
ORDER BY, COMPUTE, FOR BROWSE, or COMPUTE BY clauses cannot be used.
·
The INTO keyword cannot be used in a view.
When a view is defined with an outer join and is queried with a qualification
on a column from the inner table of the outer join, the results from SQL Server and Oracle can
differ. In most cases, Oracle views are easily translated into SQL Server views.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE VIEW STUDENT_ADMIN.STUDENT_GPA
(SSN, GPA)
AS SELECT SSN, ROUND(AVG(DECODE(grade
,'A', 4
,'A+', 4.3
,'A-', 3.7
,'B', 3
,'B+', 3.3
,'B-', 2.7
,'C', 2
,'C+', 2.3
,'C-', 1.7
,'D', 1
,'D+', 1.3
,'D-', 0.7
,0)),2)
FROM STUDENT_ADMIN.GRADE
GROUP BY SSN
|
CREATE VIEW STUDENT_ADMIN.STUDENT_GPA
(SSN, GPA)
AS SELECT SSN, ROUND(AVG(CASE grade
WHEN 'A' THEN 4
WHEN 'A+' THEN 4.3
WHEN 'A-' THEN 3.7
WHEN 'B' THEN 3
WHEN 'B+' THEN 3.3
WHEN 'B-' THEN 2.7
WHEN 'C' THEN 2
WHEN 'C+' THEN 2.3
WHEN 'C-' THEN 1.7
WHEN 'D' THEN 1
WHEN 'D+' THEN 1.3
WHEN 'D-' THEN 0.7
ELSE 0
END),2)
FROM STUDENT_ADMIN.GRADE
GROUP BY SSN
|
Microsoft SQL Server 2000 introduces indexed views. Like Oracle's materialized
views, indexed views are views that physically store their indexed result set on disk. Indexed
views are automatically updated when their base data is updated. Indexed views are capable of
providing a large boost to performance in decision-support systems in which large amounts of
data must be aggregated, or in online transaction processing (OLTP) systems in which many joins
are used to aggregate slowly changing data.
SQL Server indexed views cannot reference objects in remote databases. SQL
Server has multiple internal replication schemes including both Snapshot and Transactional
replication that provide more functionality in terms of moving data among servers.
In SQL Server, for a view to be eligible for indexing, it must be defined with
the SCHEMABINDING option that locks the underlying table schemas that the view references. The
view also cannot reference nondeterministic functions. The first index created against the view
must be a clustered unique index. This is required so SQL Server can quickly locate rows when
the data in the base schema is modified.
For more information, see "Designing an Indexed View" in SQL Server 2000 Books
Online.
Microsoft SQL Server offers
clustered and nonclustered index structures. These indexes are made up of pages that form a
branching structure known as a B-tree (similar to the Oracle B-tree index structure). The
starting page (root level) specifies ranges of values within the table. Each range on the
root-level page points to another page (decision node), which contains a more limited range of
values for the table. In turn, these decision nodes can point to other decision nodes, further
narrowing the search range. The final level in the branching structure is called the leaf
level.
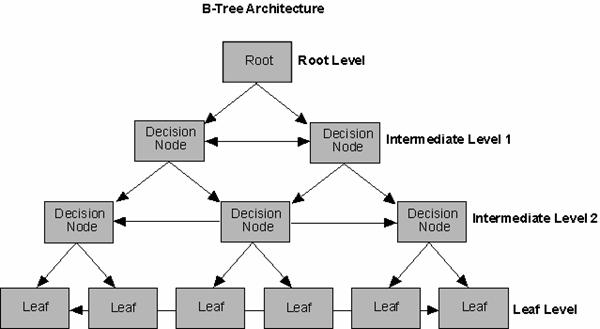
Clustered indexes are implemented in Oracle as index-organized tables. A
clustered index is an index that has been physically merged with a table. The table and index
share the same storage area. Creation of a clustered index physically rearranges the rows of
data in indexed order, forming the intermediate decision nodes. The leaf pages of the index
contain the actual table data. This architecture permits only one clustered index per table.
Unless a clustered index already exists on the table or a nonclustered index is explicitly
specified, a unique, clustered index is created to enforce the PRIMARY KEY constraint.
Clustered indexes are useful for:
·
Primary keys.
·
Columns that are not updated.
·
Queries that return a range of values, using operators such as BETWEEN, >, >=, <, and
<=, for example:
SELECT * FROM STUDENT WHERE GRAD_DATE
BETWEEN '1/1/97' AND '12/31/97'
·
Queries that return large result sets, such as:
SELECT * FROM STUDENT WHERE LNAME = 'SMITH'
·
Columns that are used in sort operations (ORDER BY, GROUP BY).
For example, on the STUDENT table, it might
be helpful to include a nonclustered index on the primary key of ssn,
and a clustered index could be created on lname, fname, (last name, first name), because this is the way students are often
grouped.
·
Distributing update activity in a table to avoid hot spots. Hot
spots are often caused by multiple users inserting into a table with an ascending key. This
application scenario is usually addressed by row-level locking.
Dropping and re-creating a clustered index is a common technique for
reorganizing a table in SQL Server. It is an easy way to ensure that data pages are contiguous
on disk, and to reestablish some free space in the table. This is similar to exporting,
dropping, and importing a table in Oracle.
A SQL Server clustered index is not at all like an Oracle cluster. An Oracle
cluster is a physical grouping of two or more tables that share the same data blocks and use
common columns as a cluster key. SQL Server does not have a structure similar to an Oracle
cluster.
As a general rule, defining a clustered index on a table improves SQL Server
performance and space management. If you do not know the query or update patterns for a given
table, you can create the clustered index on the primary key.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE TABLE STUDENT_ADMIN.GRADE (
SSNCHAR(9) NOT NULL,
CCODEVARCHAR2(4) NOT NULL,
GRADEVARCHAR2(2) NULL,
CONSTRAINT GRADE_SSN_CCODE_PK
PRIMARY KEY (SSN, CCODE)
CONSTRAINT GRADE_SSN_FK
FOREIGN KEY (SSN) REFERENCES
STUDENT_ADMIN.STUDENT (SSN),
CONSTRAINT GRADE_CCODE_FK
FOREIGN KEY (CCODE) REFERENCES
DEPT_ADMIN.CLASS (CCODE)
)
ORGANIZATION INDEX
|
CREATE TABLE STUDENT_ADMIN.GRADE (
SSNCHAR(9) NOT NULL,
CCODE
VARCHAR(4) NOT NULL,
GRADE
VARCHAR(2) NULL,
CONSTRAINT GRADE_SSN_CCODE_PK
PRIMARY KEY CLUSTERED (SSN, CCODE),
CONSTRAINT GRADE_SSN_FK
FOREIGN KEY (SSN) REFERENCES
STUDENT_ADMIN.STUDENT (SSN),
CONSTRAINT GRADE_CCODE_FK
FOREIGN KEY (CCODE) REFERENCES
DEPT_ADMIN.CLASS (CCODE)
)
|
In nonclustered indexes, the index data and the table data are physically
separate, and the rows in the table are not stored in the order of the index. You can move
Oracle index definitions to Microsoft SQL Server nonclustered index definitions (as shown in
the following example). For performance reasons, however, you might want to choose one of the
indexes of a given table and create it as a clustered index.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE INDEX
STUDENT_ADMIN.STUDENT_MAJOR_IDX
ON STUDENT_ADMIN.STUDENT (MAJOR)
TABLESPACE USER_DATA
PCTFREE 0
STORAGE (INITIAL 10K NEXT 10K
MINEXTENTS 1 MAXEXTENTS UNLIMITED)
|
CREATE NONCLUSTERED INDEX
STUDENT_MAJOR_IDX
ON USER_DB.STUDENT_ADMIN.STUDENT (MAJOR)
|
In Oracle, an index name is unique within a user account. In SQL Server, an
index name must be unique within a table name, but it does not have to be unique within a user
account or database. Therefore, when creating or dropping an index in SQL Server, you must
specify both the table name and the index name. Additionally, the SQL Server DROP INDEX statement can drop
multiple indexes at one time.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE [UNIQUE] INDEX [schema].index_name
ON [schema.]table_name
(column_name [, column_name]...)
[INITRANS n]
[MAXTRANS n]
[TABLESPACE tablespace_name]
[STORAGE storage_parameters]
[PCTFREE n]
[NOSORT]
DROP INDEX ABC;
|
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED]
INDEX index_name ON table
(column [,…n])
[WITH
[PAD_INDEX]
[[,] FILLFACTOR = fillfactor]
[[,] IGNORE_DUP_KEY]
[[,] DROP_EXISTING]
[[,] STATISTICS_NORECOMPUTE]
]
[ON file group]
DROP INDEX USER_DB.STUDENT.DEMO_IDX, USER_DB.GRADE.DEMO_IDX
|
The FILLFACTOR option in SQL Server functions in much the same way as the
PCTFREE variable does in Oracle. As tables grow in size, index pages split to accommodate new
data. The index must reorganize itself to accommodate new data values. The fill factor
percentage is used only when the index is created, and it is not maintained afterwards.
The FILLFACTOR option (values are 0 through 100) controls how much space is
left on an index page when the index is initially created. The default fill factor of 0 is used
if none is specified-this will completely fill index leaf pages and leave space on each
decision node page for at least one entry (two for nonunique clustered indexes).
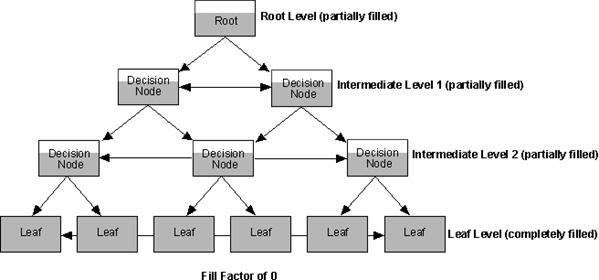
A lower fill factor value initially reduces the splitting of index pages and
increases the number of levels in the B-tree index structure. A higher fill factor value uses
index page space more efficiently, requires fewer disk I/Os to access index data, and reduces
the number of levels in the B-tree index structure.
The PAD_INDEX option specifies that the fill factor setting be applied to the
decision node pages as well as to the data pages in the index.
Although it may be necessary to adjust the PCTFREE parameter for optimal
performance in Oracle, it is seldom necessary to include the FILLFACTOR option in a CREATE
INDEX statement. The fill factor is provided for fine-tuning performance. It is useful only
when creating a new index on a table with existing data, and then it is useful only when you
can accurately predict future changes in that data.
If you have set PCTFREE to 0 for your Oracle indexes, consider using a fill
factor of 100. This is used when there will be no inserts or updates occurring in the table (a
read-only table). When fill factor is set to 100, SQL Server creates indexes with each page 100
percent full.
With both Oracle and SQL Server, users cannot insert duplicate values for a
uniquely indexed column or columns. An attempt to do so generates an error message.
Nevertheless, SQL Server lets the developer choose how the INSERT or UPDATE statement will
respond to the error.
If IGNORE_DUP_KEY was specified in the CREATE INDEX statement, and an INSERT or
UPDATE statement that creates a duplicate key is executed, SQL Server issues a warning message
and ignores (does not insert) the duplicate row. If IGNORE_DUP_KEY was not specified for the
index, SQL Server issues an error message and rolls back the entire INSERT statement. For more
information about these options, see SQL Server 2000 Books Online.
Oracle allows you to place an index directly on a function. Microsoft SQL
Server allows for indexes to be placed on computed columns within a table. Within SQL Server, a
table can consist of multiple computed columns but must have at least one noncomputed column.
Computed columns can consist either of SQL Server functions or user-defined functions or other
expressions, but all expressions must be deterministic in nature. That is, the expression must
return the same value each time it is called with identical parameters. For example, the SQL
Server GETDATE() function is nondeterministic because it is always called with the same
parameters and returns a different value each time.
For more information, see "Creating Indexes on Computed Columns" in SQL Server
2000 Books Online.
An Oracle application might have to create tables that exist for short periods.
The application must ensure that all tables created for this purpose are dropped at some point.
If the application fails to do this, tablespaces can quickly become cluttered and
unmanageable.
Microsoft SQL Server provides temporary table database objects, which are
created for just such a purpose. These tables are always created in the tempdb database. The table name determines how long they reside within the
tempdb database.
|
Table name
|
Description
|
|
#table_name
|
This local temporary table only exists for the duration of a user session
or the procedure that created it. It is automatically dropped when the user logs off or
the procedure that created the table completes. These tables cannot be shared between
multiple users. No other database users can access this table. Permissions cannot be
granted or revoked on this table.
|
|
##table_name
|
This global temporary table also typically exists for the duration of a
user session or procedure that created it. This table can be shared among multiple users.
It is automatically dropped when the last user session referencing it disconnects. All
other database users can access this table. Permissions cannot be granted or revoked on
this table.
|
Indexes can be defined for temporary tables. Views can be defined only on
tables explicitly created in tempdb without the # or ## prefix. The
following example shows the creation of a temporary table and its associated index. When the
user exits, the table and index are automatically dropped.
SELECT SUM(ISNULL(TUITION_PAID,0)) SUM_PAID, MAJOR INTO #SUM_STUDENT
FROM USER_DB.STUDENT_ADMIN.STUDENT GROUP BY MAJOR
CREATE UNIQUE INDEX SUM STUDENT IDX ON #SUM STUDENT (MAJOR)
You may find that the benefits associated with using temporary tables justify a
revision in your program code.
Although some data type conversions from Oracle to SQL Server are
straightforward, other data type conversions will require evaluating a few options. It is
recommended that you use the DTS Import/Export Wizard to automate the creation of the new
CREATE TABLE statements. These statements will provide you with the recommended conversion of
the data types. You can then modify these statements as necessary.
|
Oracle
|
Microsoft SQL Server
|
|
CHAR
|
char is recommended. char type columns are accessed somewhat faster than varchar columns because they use a fixed storage length.
|
|
VARCHAR2 and LONG
|
varchar or text. (If
the length of the data values in your Oracle column is 8000 bytes or less, use
varchar; otherwise, you must use text.)
|
|
RAW and LONG RAW
|
varbinary or image.
(If the length of the data values in your Oracle column is 8000 bytes or less, use
varbinary; otherwise, you must use image.)
|
|
NUMBER
|
If integer between 1 and 255, use tinyint.
If integer between -32768 and 32767, use smallint.
If integer between -2,147,483,648 and 2,147,483,647 use int.
If integer between -2^63 and 2^63 use bigint.
If you require a float type number, use numeric (has precision
and scale).
Note: Do not use float or
real, because rounding may occur (Oracle NUMBER and SQL Server
numeric do not round).
If you are not sure, use numeric; it most closely resembles
Oracle NUMBER data type.
|
|
DATE
|
datetime.
|
|
ROWID
|
Use the identity column type or the
uniqueidentifier data type and the NEWID function.
|
|
CURRVAL, NEXTVAL
|
Use the identity column type, and @@IDENTITY
global variable, IDENT_SEED() and IDENT_INCR() functions.
|
|
SYSDATE
|
GETDATE()
|
|
USER
|
USER
|
The Unicode specification defines a single encoding scheme for practically all
characters widely used in businesses around the world. All computers consistently translate the
bit patterns in Unicode data into characters using the single Unicode specification. This
ensures that the same bit pattern is always converted to the same character on all computers.
Data can be freely transferred from one database or computer to another without concern that
the receiving system will correctly translate the bit patterns into characters.
One problem with data types that use 1 byte to encode each character is that
the data type can represent only 256 different characters. This forces multiple encoding
specifications (or code pages) for different alphabets. It is also impossible to handle systems
such as the Japanese Kanji or Korean Hangul alphabets that have thousands of characters.
Microsoft SQL Server translates the bit patterns in char, varchar, and text
columns to characters using the definitions in the code page installed with SQL Server. Client
computers use the code page installed with the operating system to interpret character bit
patterns. There are many different code pages. Some characters appear on some code pages, but
not on others. Some characters are defined with one bit pattern on some code pages, and with a
different bit pattern on other code pages. When you build international systems that must
handle different languages, it becomes difficult to pick code pages for all the computers that
meet the language requirements of multiple countries. It is also difficult to ensure that every
computer performs the correct translations when interfacing with a system that uses a different
code page.
The Unicode specification addresses this problem by using 2 bytes to encode
each character. There are enough different patterns (65,536) in 2 bytes for a single
specification covering the most common business languages. Because all Unicode systems
consistently use the same bit patterns to represent all characters, there is no problem with
characters being converted incorrectly when moving from one system to another.
In SQL Server, nchar, nvarchar, and ntext data types support Unicode data.
For more information about SQL Server data types, see SQL Server 2000 Books
Online.
User-defined data types can
be created for the model database or for a single-user database. If
the user-defined data type is defined for model, that data type is
available to all new user databases created from that point forward. The user-defined data type
is defined with the sp_addtype system stored procedure. For more
information, see SQL Server 2000 Books Online.
You can use a user-defined data type in the CREATE TABLE and ALTER TABLE
statements, and bind defaults and rules to it. If nullability is explicitly defined when the
user-defined data type is used during table creation, it takes precedence over the nullability
defined when the data type was created.
This example shows how to create a user-defined data type. The arguments are
the user-type name, data type, and nullability:
sp_addtype gender_type, 'varchar(1)', 'not null'
go
This capability might initially appear to solve the problem of migrating Oracle
table creation scripts to SQL Server. For example, it is quite easy to add the Oracle DATE data
type:
sp_addtype date, datetime
This does not work with data types that require variable sizes, such as the
Oracle data type NUMBER. An error message is returned indicating that a length must also be
specified:
sp_addtype varchar2, varchar
Go
Msg 15091, Level 16, State 1
You must specify a length with this physical type.
The timestamp columns enable BROWSE-mode updates and
make cursor update operations more efficient. The timestamp is a data
type that is automatically updated every time a row containing a timestamp column is inserted or updated.
Values in timestamp columns are not stored as an
actual date or time, but are stored as binary(8) or varbinary(8), which indicates the sequence of events on rows in the table. A
table can have only one timestamp column.
For more information, see SQL Server 2000 Books Online.
Microsoft SQL Server object privileges can be granted to, denied from, and
revoked from other database users, database groups, and the public
role. SQL Server does not allow an object owner to grant ALTER TABLE and CREATE INDEX
privileges for the object as Oracle does. Those privileges must remain with the object
owner.
The GRANT statement creates an entry in the security system that allows a user
in the current database to work with data in the current database or to execute specific
Transact‑SQL statements. The syntax of the GRANT statement is identical in Oracle and SQL
Server.
The Transact‑SQL DENY statement creates an entry in the security system
that denies a permission from a security account in the current database and prevents the
security account from inheriting the permission through its group or role memberships. Oracle
does not have a DENY statement.
The Transact‑SQL REVOKE statement removes a previously granted or denied
permission from a user in the current database.
|
Oracle
|
Microsoft SQL Server
|
|
GRANT {ALL [PRIVILEGES][column_list] |
permission_list [column_list]}
ON {table_name [(column_list)]
| view_name [(column_list)]
| stored_procedure_name}
TO {PUBLIC | name_list }
[WITH GRANT OPTION]
|
GRANT
{ALL [PRIVILEGES] | permission[,…n]}
{
[(column[,…n])] ON {table | view}
| ON {table |
view}[(column[,…n])]
| ON {stored_procedure | extended_procedure}
}
TO security_account[,…n]
[WITH GRANT OPTION]
[AS {group | role}]
REVOKE [GRANT OPTION FOR]
{ALL [PRIVILEGES] | permission[,…n]}
{
[(column[,…n])] ON {table |
view}
| ON {table |
view}[(column[,…n])]
| {stored_procedure | extended_procedure}
}
{TO | FROM}
security_account[,…n]
[CASCADE]
[AS {group | role}]
DENY
{ALL [PRIVILEGES] | permission[,…n]}
{
[(column[,…n])] ON {table | view}
| ON {table |
view}[(column[,…n])]
| ON {stored_procedure | extended_procedure}
}
TO security_account[,…n]
[CASCADE]
|
For more information about object-level permissions, see SQL Server 2000 Books
Online.
In Oracle, the REFERENCES privilege can be granted only to a user. SQL Server
allows the REFERENCES privilege to be granted to both database users and database groups. The
INSERT, UPDATE, DELETE, and SELECT privileges are granted in the same way in both Oracle and
SQL Server.
Enforcing data integrity ensures the quality of the data in the database. Two
important steps when planning tables are identifying valid values for a column and deciding how
to enforce the integrity of the data in the column. Data integrity falls into four categories,
and is enforced in various ways.
|
Integrity type
|
How enforced
|
|
Entity integrity
|
PRIMARY KEY constraint
UNIQUE constraint
IDENTITY property
|
|
Domain integrity
|
Domain DEFAULT definition
FOREIGN KEY constraint
CHECK constraint
Nullability
|
|
Referential integrity
|
FOREIGN KEY constraint
CHECK constraint
|
|
User-defined integrity
|
All column- and table-level constraints in CREATE TABLE
Stored procedures
Triggers
|
Entity integrity defines a row as a unique entity for a particular table.
Entity integrity enforces the integrity of the identifier column(s) or the primary key of a
table through indexes, UNIQUE constraints, PRIMARY KEY constraints, or IDENTITY properties.
You should always name your constraints explicitly. If you do not, Oracle and
Microsoft SQL Server will use different naming conventions to name the constraint implicitly.
These differences in naming can complicate your migration process unnecessarily. The
discrepancy appears when dropping or disabling constraints, because constraints must be dropped
by name. The syntax for explicitly naming constraints is the same for Oracle and SQL
Server:
CONSTRAINT constraint_name
The SQL-92 standard requires that all values in a primary key be unique and
that the column not allow null values. Both Oracle and Microsoft SQL Server enforce uniqueness
by automatically creating unique indexes whenever a PRIMARY KEY or UNIQUE constraint is
defined. Additionally, primary key columns are automatically defined as NOT NULL. Only one
primary key is allowed per table.
A SQL Server clustered index is created by default for a primary key, though a
nonclustered index can be requested. The Oracle index on primary keys can be removed by either
dropping or disabling the constraint, whereas the SQL Server index can be removed only by
dropping the constraint.
In either RDBMS, alternate keys can be defined with a UNIQUE constraint.
Multiple UNIQUE constraints can be defined on any table. UNIQUE constraint columns are
nullable. In SQL Server, a nonclustered index is created by default, unless otherwise
specified.
When migrating your application, it is important to note that SQL Server allows
only one row to contain the value NULL for the complete unique key (single or multiple column
index), and Oracle allows any number of rows to contain the value NULL for the complete unique
key.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE TABLE DEPT_ADMIN.DEPT
(DEPT VARCHAR2(4) NOT NULL,
DNAME VARCHAR2(30) NOT NULL,
CONSTRAINT DEPT_DEPT_PK
PRIMARY KEY (DEPT)
USING INDEX TABLESPACE USER_DATA
PCTFREE 0 STORAGE (
INITIAL 10K NEXT 10K
MINEXTENTS 1 MAXEXTENTS UNLIMITED),
CONSTRAINT DEPT_DNAME_UNIQUE
UNIQUE (DNAME)
USING INDEX TABLESPACE USER_DATA
PCTFREE 0 STORAGE (
INITIAL 10K NEXT 10K
MINEXTENTS 1 MAXEXTENTS UNLIMITED)
)
|
CREATE TABLE USER_DB.DEPT_ADMIN.DEPT
(DEPTVARCHAR(4) NOT NULL,
DNAMEVARCHAR(30) NOT NULL,
CONSTRAINT DEPT_DEPT_PK
PRIMARY KEY CLUSTERED (DEPT),
CONSTRAINT DEPT_DNAME_UNIQUE
UNIQUE NONCLUSTERED (DNAME)
)
|
Disabling constraints can improve database performance and streamline the data
replication process. For example, when you rebuild or replicate table data at a remote site,
you do not have to repeat constraint checks, because the integrity of the data was checked when
it was originally entered into the table. You can program an Oracle application to disable and
enable constraints (except for PRIMARY KEYand UNIQUE). It is recommended that you use the NOT
FOR REPLICATION clause to suspend column-level, foreign key, and CHECK constraints during
replication.
In cases where you are not replicating data, and need to remove a constraint,
you can accomplish this in Microsoft SQL Server using the CHECK and WITH NOCHECK options with
the ALTER TABLE statement.
This illustration shows a comparison of this process.
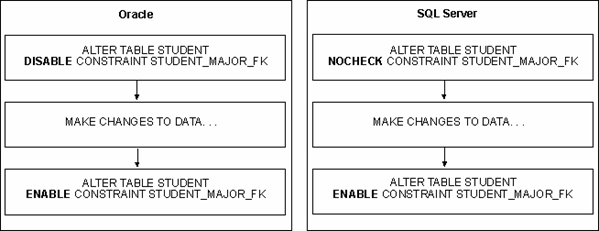
With SQL Server, you can defer all of the table constraints by using the ALL
keyword with the NOCHECK clause.
If your Oracle application uses the CASCADE option to disable or drop PRIMARY
KEY or UNIQUE constraints, you may need to rewrite some code because the CASCADE option
disables or drops both the parent and any related child integrity constraints.
This is an example of the syntax:
DROP CONSTRAINT DEPT_DEPT_PK CASCADE
The SQL Server-based application must be modified to first drop the child
constraints and then the parent constraints. For example, in order to drop the PRIMARY KEY
constraint on the DEPT table, the foreign keys for the columns
STUDENT.MAJOR and CLASS.DEPT must be
dropped. This is an example of the syntax:
ALTER TABLE STUDENT
DROP CONSTRAINT STUDENT_MAJOR_FK
ALTER TABLE CLASS
DROP CONSTRAINT CLASS_DEPT_FK
ALTER TABLE DEPT
DROP CONSTRAINT DEPT_DEPT_PK
The ALTER TABLE syntax that adds and drops constraints is almost identical for
Oracle and SQL Server.
A SQL Server table can have one column defined as an identity column, which is
an auto-incrementing integer field. SQL Server automatically tracks inserts and adds the value
for the identity column to the record. If your application uses Oracle SEQUENCE to generate
unique integers for a column, then you can replace it with the identity field.
|
Category
|
Microsoft SQL Server IDENTITY
|
|
Syntax
|
CREATE TABLE new_employees
( Empid int IDENTITY (1,1), Employee_Name varchar(60),
CONSTRAINT Emp_PK PRIMARY KEY (Empid)
)
If increment interval is 5:
CREATE TABLE new_employees
( Empid int IDENTITY (1,5), Employee_Name varchar(60),
CONSTRAINT Emp_PK PRIMARY KEY (Empid)
)
|
|
Identity columns per table
|
One
|
|
Null values allowed
|
No
|
|
Use of default constraints, values
|
Cannot be used.
|
|
Enforcing uniqueness
|
Yes
|
|
Querying for maximum current identity number after an INSERT, SELECT
INTO, or bulk copy statement completes
|
@@IDENTITY (function)
|
|
Returns the seed value specified during the creation of an identity
column
|
IDENT_SEED('table_name')
|
|
Returns the increment value specified during the creation of an identity
column
|
IDENT_INCR('table_name')
|
|
SELECT syntax
|
The keyword IDENTITYCOL can be used in place of a column name when you
reference a column that has the IDENTITY property, in SELECT, INSERT, UPDATE, and DELETE
statements.
|
Although the IDENTITY property automates row numbering within one table,
separate tables, each with its own identifier column, can generate the same values. This is
because the IDENTITY property is guaranteed to be unique only for the table on which it is
used. If an application must generate an identifier column that is unique across the entire
database, or every database on every networked computer in the world, use the ROWGUIDCOL
property, the uniqueidentifier data type, and the NEWID function. SQL
Server uses globally unique identifier columns for merge replication to ensure that rows are
uniquely identified across multiple copies of the table.
If your application uses an Oracle SEQUENCE to generate a unique value that is
then concatenated with another value to produce a unique string, you will have to create some
custom code, either in a trigger or stored procedure that will generate the concatenated string
for you.
For more information about creating and modifying uniqueidentifier columns, see SQL Server 2000 Books Online.
Domain integrity enforces valid entries for a given column. Domain integrity is
enforced by restricting the type (through data types), the format (through CHECK constraints),
or the range of possible values (through REFERENCE and CHECK constraints).
Oracle treats a default as a column property, and Microsoft SQL Server treats a
default as a constraint. The SQL Server DEFAULT constraint can contain constant values,
built-in functions that do not take arguments (niladic functions), or NULL.
To easily migrate the Oracle DEFAULT column property, you should define DEFAULT
constraints at the column level in SQL Server without applying constraint names. SQL Server
generates a unique name for each DEFAULT constraint.
The syntax used to define CHECK constraints is the same in Oracle and SQL
Server. The search condition must evaluate to a Boolean expression and cannot contain
subqueries. A column-level CHECK constraint can reference only the constrained column, and a
table-level check constraint can reference only columns of the constrained table. Multiple
CHECK constraints can be defined for a table. SQL Server syntax allows only one column-level
CHECK constraint to be created on a column in a CREATE TABLE statement, and the constraint can
have multiple conditions.
The best way to test your modified CREATE TABLE statements is to use the SQL
Query Analyzer in SQL Server, and parse only the syntax. The Results pane indicates any errors.
For more information about constraint syntax, see SQL Server 2000 Books Online.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE TABLE STUDENT_ADMIN.STUDENT (
SSN CHAR(9) NOT NULL,
FNAME VARCHAR2(12) NULL,
LNAME VARCHAR2(20) NOT NULL,
GENDER CHAR(1) NOT NULL
CONSTRAINT STUDENT_GENDER_CK
CHECK (GENDER IN ('M','F')),
MAJOR VARCHAR2(4)
DEFAULT 'Undc' NOT NULL,
BIRTH_DATE DATE NULL,
TUITION_PAID NUMBER(12,2) NULL,
TUITION_TOTAL NUMBER(12,2) NULL,
START_DATE DATE NULL,
GRAD_DATE DATE NULL,
LOAN_AMOUNT NUMBER(12,2) NULL,
DEGREE_PROGRAM CHAR(1)
DEFAULT 'U' NOT NULL
CONSTRAINT STUDENT_DEGREE_CK CHECK
(DEGREE_PROGRAM IN ('U', 'M', 'P', 'D')),
...
|
CREATE TABLE USER_DB.STUDENT
_ADMIN.STUDENT (
SSN CHAR(9) NOT NULL,
FNAME VARCHAR(12) NULL,
LNAME VARCHAR(20) NOT NULL,
GENDER CHAR(1) NOT NULL
CONSTRAINT STUDENT_GENDER_CK
CHECK (GENDER IN ('M','F')),
MAJOR VARCHAR(4)
DEFAULT 'Undc' NOT NULL,
BIRTH_DATE DATETIME NULL,
TUITION_PAID NUMERIC(12,2) NULL,
TUITION_TOTAL NUMERIC(12,2) NULL,
START_DATE DATETIME NULL,
GRAD_DATE DATETIME NULL,
LOAN_AMOUNT NUMERIC(12,2) NULL,
DEGREE_PROGRAM CHAR(1)
DEFAULT 'U' NOT NULL
CONSTRAINT STUDENT_DEGREE_CK
CHECK
(DEGREE_PROGRAM IN ('U', 'M', 'P', 'D')),
...
|
Note The syntax for
Microsoft SQL Server rules and defaults remains for backward compatibility purposes, but CHECK
constraints and DEFAULT constraints are recommended for new application development. For more
information, see SQL Server 2000 Books Online.
Microsoft SQL Server and Oracle create column constraints to enforce
nullability. An Oracle column defaults to NULL, unless NOT NULL is specified in the CREATE
TABLE or ALTER TABLE statements. In Microsoft SQL Server, database and session settings can
override the nullability of the data type used in a column definition.
All of your SQL scripts (whether Oracle or SQL Server) should explicitly define
both NULL and NOT NULL for each column. When not explicitly specified, column nullability
follows these rules.
|
Null Setting
|
Description
|
|
Column is defined with a user-defined data type
|
SQL Server uses the nullability specified when the data type was created.
Use the sp_help system stored procedure to get the data type's
default nullability.
|
|
Column is defined with a system-supplied data type
|
If the system-supplied data type has
only one option, it takes precedence. The bit data type can be
defined as 0, 1 or NULL.
If any session settings are ON (set with the SET), then:
If ANSI_NULL_DFLT_ON is ON,
NULL is assigned.
If ANSI_NULL_DFLT_OFF is ON, NOT NULL is assigned.
If any database settings are configured (changed with the ALTER DATABASE statement),
then:
If ANSI NULL DEFAULT is TRUE, NULL is assigned.
If ANSI NULL DEFAULT is FALSE, NOT NULL is assigned.
|
|
NULL/NOT NULL
Not defined
|
When not explicitly defined (neither of the ANSI_NULL_DFLT options are
set), the session setting has not been changed, and the database is set to the default
(ANSI NULL DEFAULT is FALSE), then SQL Server assigns it NOT NULL.
|
The table provides a comparison of the syntax used to define referential
integrity constraints.
|
Constraint
|
Oracle
|
Microsoft SQL Server
|
|
PRIMARY KEY
|
[CONSTRAINT constraint_name]
PRIMARY KEY (col_name [, col_name2 [..., col_name16]])
[USING INDEX storage_parameters]
|
[CONSTRAINT constraint_name]
PRIMARY KEY [CLUSTERED | NONCLUSTERED] (col_name [,
col_name2 [..., col_name16]])
[ON segment_name]
[NOT FOR REPLICATION]
|
|
UNIQUE
|
[CONSTRAINT constraint_name]
UNIQUE (col_name [, col_name2
[..., col_name16]])
[USING INDEX storage_parameters]
|
[CONSTRAINT constraint_name]
UNIQUE [CLUSTERED | NONCLUSTERED](col_name [, col_name2 [..., col_name16]])
[ON segment_name]
[NOT FOR REPLICATION]
|
|
Constraint (continued)
|
Oracle (continued)
|
Microsoft SQL Server (continued)
|
|
FOREIGN KEY
|
[CONSTRAINT constraint_name]
[FOREIGN KEY (col_name [, col_name2 [..., col_name16]])]
REFERENCES [owner.]ref_table
[(ref_col [, ref_col2 [...,
ref_col16]])]
[ON DELETE CASCADE]
|
[CONSTRAINT constraint_name]
[FOREIGN KEY (col_name [, col_name2 [..., col_name16]])]
REFERENCES [owner.]ref_table
[(ref_col [, ref_col2 [...,
ref_col16]])]
[ON DELETE CASCADE | No Action]
[ON UPDATE CASCADE | No Action]
[NOT FOR REPLICATION]
|
|
DEFAULT
|
Column property, not a constraint
DEFAULT (constant_expression)
|
[CONSTRAINT constraint_name]
DEFAULT {constant_expression | niladic-function | NULL}
[FOR col_name]
[NOT FOR REPLICATION]
|
|
CHECK
|
[CONSTRAINT constraint_name]
CHECK (expression)
|
[CONSTRAINT constraint_name]
CHECK [NOT FOR REPLICATION] (expression)
|
The NOT FOR REPLICATION clause is used to suspend column-level, FOREIGN KEY,
and CHECK constraints during replication.
The rules for defining foreign keys are similar in each RDBMS. The number of
columns and data type of each column specified in the foreign key clause must match the
REFERENCES clause. A nonnull value entered in this column(s) must exist in the table and
column(s) defined in the REFERENCES clause, and the referenced table's columns must have a
PRIMARY KEY or UNIQUE constraint.
Microsoft SQL Server constraints provide the ability to reference tables within
the same database. To implement referential integrity across databases, use table-based
triggers.
Both Oracle and SQL Server support self-referenced tables, tables in which a
reference (foreign key) can be placed against one or more columns on the same table. For
example, the column prereq in the CLASS
table can reference the column ccode in the CLASS table to ensure that a valid course code is entered as a course
prerequisite.
In SQL Server 2000, foreign keys have an ON DELETE and an ON UPDATE clause that
are used to define what action should be taken if a candidate key to which the foreign key is
pointing is deleted or modified. The NO ACTION option causes the delete or update statement to
fail with an error. The CASCADE option ON DELETE cascades the delete to any rows that reference
the data within the FOREIGN KEY constraint. The CASCADE option ON UPDATE automatically
propagates the modification to any rows that reference the data within the KOREIGN KEY
constraint.
User-defined integrity allows you to define specific business rules that do not
fall into one of the other integrity categories.
Microsoft SQL Server stored procedures use the CREATE PROCEDURE statement to
accept and return user-supplied parameters. With the exception of temporary stored procedures,
stored procedures are created in the current database. The table shows the syntax for Oracle
and SQL Server.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE OR REPLACE PROCEDURE [user.]procedure
[(argument [IN | OUT] datatype
[, argument [IN | OUT] datatype]
{IS | AS} block
|
CREATE PROC[EDURE] procedure_name
[;number]
[
{@parameter
data_type} [VARYING] [= default] [OUTPUT]
]
[,…n]
[WITH
{ RECOMPILE | ENCRYPTION | RECOMPILE,
ENCRYPTION} ]
[FOR REPLICATION]
AS
sql_statement […n]
|
In SQL Server, temporary procedures are created in the tempdb database by prefacing procedure_name with a
single number sign (#procedure_name) for local temporary procedures
and with a double number sign (##procedure_name) for global
temporary procedures.
A local temporary procedure can be used only by the user who created it.
Permission to execute a local temporary procedure cannot be granted to other users. Local
temporary procedures are automatically dropped at the end of the user session.
A global temporary procedure is available to all SQL Server users. If a global
temporary procedure is created, all users can access it, and permissions cannot be explicitly
revoked. Global temporary procedures are dropped at the end of the last user session using the
procedure.
SQL Server stored procedures can be nested up to 32 levels. The nesting level
is incremented when the called procedure starts execution, and it is decremented when the
called procedure finishes execution.
The following example shows how a Transact‑SQL stored procedure can be
used to replace an Oracle PL/SQL packaged function. In this example, the Transact‑SQL
version is much simpler because of the ability of SQL Server to return result sets directly
from SELECT statements in a stored procedure, without using a cursor.
Oracle
|
Microsoft SQL Server
|
|
CREATE OR REPLACE PACKAGE STUDENT_ADMIN.P1 AS
ROWCOUNT NUMBER :=0;
CURSOR C1 RETURN STUDENT%ROWTYPE;
FUNCTION SHOW_RELUCTANT_STUDENTS
(WORKVAR OUT VARCHAR2) RETURN NUMBER;
END P1;
/
CREATE OR REPLACE PACKAGE BODY STUDENT_ADMIN.P1 AS
CURSOR C1 RETURN STUDENT%ROWTYPE IS
SELECT * FROM STUDENT_ADMIN.STUDENT
WHERE NOT EXISTS
(SELECT 'X' FROM STUDENT_ADMIN.GRADE
WHERE GRADE.SSN=STUDENT.SSN) ORDER BY SSN;
FUNCTION SHOW_RELUCTANT_STUDENTS
(WORKVAR OUT VARCHAR2) RETURN NUMBER IS
WORKREC STUDENT%ROWTYPE;
BEGIN
IF NOT C1%ISOPEN THEN OPEN C1;
ROWCOUNT :=0;
ENDIF;
FETCH C1 INTO WORKREC;
IF (C1%NOTFOUND) THEN
CLOSE C1;
ROWCOUNT :=0;
ELSE
WORKVAR := WORKREC.FNAME||'
'||WORKREC.LNAME||
', social security number '||WORKREC.SSN||' is not enrolled
in any classes!';
ROWCOUNT := ROWCOUNT + 1;
ENDIF;
RETURN(ROWCOUNT);
EXCEPTION
WHEN OTHERS THEN
IF C1%ISOPEN THEN CLOSE C1;
ROWCOUNT :=0;
ENDIF;
RAISE_APPLICATION_ERROR(-20001,SQLERRM);
END SHOW_RELUCTANT_STUDENTS;
END P1;
/
|
CREATE PROCEDURE
STUDENT_ADMIN.SHOW_RELUCTANT_STUDENTS
AS SELECT FNAME+'' +LNAME+', social security
number'+ SSN+' is not enrolled in any classes!'
FROM STUDENT_ADMIN.STUDENT S
WHERE NOT EXISTS
(SELECT 'X' FROM STUDENT_ADMIN.GRADE G
WHERE G.SSN=S.SSN)
ORDER BY SSN
RETURN@@ROWCOUNT
GO
|
SQL Server does not support constructs similar to Oracle packages, and does not
support the CREATE OR REPLACE option for creating stored procedures. Instead, SQL Server
supports either the CREATE or ALTER statements to create or modify stored
procedures.
Microsoft SQL Server provides WAITFOR, which allows developers to specify a
time, time interval, or event that triggers the execution of a statement block, stored
procedure, or transaction. This is the Transact‑SQL equivalent to the Oracle
dbms_lock.sleep.
WAITFOR {DELAY 'time' | TIME 'time'}
where
DELAY:
Instructs Microsoft SQL Server to wait until the specified amount of time
has passed, up to a maximum of 24 hours.
'time'
The amount of time to wait. time can be
specified in one of the acceptable formats for datetime data, or it
can be specified as a local variable. Dates cannot be specified; therefore, the data portion of
the datetime value is not allowed.
TIME:
Instructs SQL Server to wait until the specified time.
For example:
BEGIN
WAITFOR TIME '22:20'
EXECUTE update_all_stats
END
To specify a parameter within a stored procedure, use this syntax.
|
Oracle
|
Microsoft SQL Server
|
|
Varname datatype
DEFAULT <value>;
|
{@parameter data_type} [VARYING]
[= default] [OUTPUT]
|
Both Oracle and Microsoft SQL Server have triggers, which have some differences
in their implementations.
|
Description
|
Oracle
|
Microsoft SQL Server
|
|
Number of triggers per table
|
Unlimited
|
Unlimited
|
|
Triggers executed before INSERT, UPDATE, DELETE
|
Yes
|
Yes. This functionality can be created with the INSTEAD OF option.
|
|
Triggers executed after INSERT, UPDATE, DELETE
|
Yes
|
Yes
|
|
Statement Level Triggers
|
Yes
|
Yes
|
|
Row Level Triggers
|
Yes
|
No
|
|
Constraints checked prior to execution
|
Yes, unless trigger is disabled.
|
Yes. In addition, this is an option in Data Transformation Services.
|
|
Referring to old or previous values in an UPDATE or DELETE trigger
|
:old
|
DELETED.column
|
|
Referring to new values in an INSERT trigger
|
:new
|
INSERTED.column
|
|
Disabling Triggers
|
ALTER TRIGGER
|
ALTER TABLE
|
Triggers can be created to execute either after (AFTER trigger) the INSERT,
UPDATE or DELETE statement or INSTEAD OF the statement. If you need the functionality of a
BEFORE trigger from Oracle, you will have to add the INSERT, UPDATE or DELETE statement to the
logic within the INSTEAD OF trigger.
The deleted and inserted
tables are logical (conceptual) tables created by SQL Server for trigger statements. They are
structurally similar to the table on which the trigger is defined and hold the old values or
new values of the rows that might be changed by the user action. The tables track row-level
changes in Transact‑SQL. These tables provide the same functionality as Oracle row-level
triggers. When an INSERT, UPDATE, or DELETE statement is executed in SQL Server, rows are added
to the trigger table and to the inserted and deleted table(s) simultaneously.
The inserted and deleted
tables are identical to the trigger table. They have the same column names and the same data
types. For example, if a trigger is placed on the GRADE table, the
inserted and deleted tables have this
structure.
|
GRADE
|
inserted
|
deleted
|
|
SSN CHAR(9)
CCODE VARCHAR(4)
GRADE VARCHAR(2)
|
SSN CHAR(9)
CCODE VARCHAR(4)
GRADE VARCHAR(2)
|
SSN CHAR(9)
CCODE VARCHAR(4)
GRADE VARCHAR(2)
|
The inserted and deleted
tables can be examined by the trigger to determine what types of trigger actions should be
carried out. The inserted table is used with the INSERT and UPDATE
statements. The deleted table is used with DELETE and UPDATE
statements.
The UPDATE statement uses both the inserted and
deleted tables because SQL Server always deletes the old row and
inserts a new row whenever an UPDATE operation is performed. Consequently, when an UPDATE is
performed, the rows in the inserted table are always duplicates of
the rows in the deleted table.
The following example uses the inserted and
deleted tables to replace a PL/SQL row-level trigger. A full outer
join is used to query all rows from either table.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE TRIGGER STUDENT_ADMIN.TRACK_GRADES
AFTER
INSERT OR UPDATE OR DELETE
ON STUDENT_ADMIN.GRADE
FOR EACH ROW
BEGIN
INSERT INTO GRADE_HISTORY(
TABLE_USER, ACTION_DATE,
OLD_SSN, OLD_CCODE, OLD_GRADE,
NEW_SSN, NEW_CCODE, NEW_GRADE)
VALUES (USER, SYSDATE,
:OLD.SSN, :OLD.CCODE, :OLD.GRADE,
:NEW.SSN, :NEW.CCODE, :NEW.GRADE),
END;
|
CREATE TRIGGER STUDENT_ADMIN.TRACK_GRADES
ON STUDENT_ADMIN.GRADE
FORAFTER INSERT, UPDATE, DELETE
AS
INSERT INTO GRADE_HISTORY(
TABLE_USER, ACTION_DATE,
OLD_SSN, OLD_CCODE, OLD_GRADE
NEW_SSN, NEW_CCODE, NEW_GRADE)
SELECT USER, GETDATE(),
OLD.SSN, OLD.CCODE, OLD.GRADE,
NEW.SSN, NEW.CCODE, NEW.GRADE
FROM INSERTED NEW FULL OUTER JOIN
DELETED OLD ON NEW.SSN = OLD.SSN
|
You can create a trigger only in the current database, though you can reference
objects outside the current database. If you use an owner name to qualify a trigger, qualify
the table name the same way.
There can be multiple AFTER triggers defined for each data modification event
for a table. However, there can be only one INSTEAD OF trigger defined for a
table.
Triggers can be nested 32 levels deep. If a trigger changes a table on which
there is another trigger, the second trigger is activated and can then call a third trigger,
and so on. If any trigger in the chain sets off an infinite loop, the nesting level is exceeded
and the trigger is canceled. Additionally, if an update trigger on one column of a table
results in an update to another column, the update trigger is activated only once. SQL Server
declarative referential integrity (DRI) does not provide cross-database referential integrity.
If cross-database referential integrity is required, use triggers. The following statements are
not allowed in a Transact‑SQL trigger:
·
CREATE statements (DATABASE, TABLE, INDEX, PROCEDURE, DEFAULT, RULE, TRIGGER, SCHEMA, and
VIEW)
·
DROP statements (TRIGGER, INDEX, TABLE, PROCEDURE, DATABASE, VIEW, DEFAULT, RULE)
·
ALTER statements (DATABASE, TABLE, VIEW, PROCEDURE, TRIGGER)
·
TRUNCATE TABLE
·
GRANT, REVOKE, DENY
·
UPDATE STATISTICS
·
RECONFIGURE
·
UPDATE STATISTICS
·
RESTORE DATABASE, RESTORE LOG
·
LOAD LOG, DATABASE
·
DISK statements
·
SELECT INTO (because it creates a table)
For more information about triggers, see SQL Server 2000 Books
Online.
This section explains how
transactions are executed in both Oracle and Microsoft SQL Server and presents the differences
between the locking processes and concurrency issues in both database types.
In Oracle, a transaction is started automatically when an insert, update, or
delete operation is performed. An application must issue a COMMIT command to save changes to
the database. If a COMMIT is not performed, all changes are rolled back or undone
automatically.
By default, SQL Server automatically performs a COMMIT statement after every
insert, update, or delete operation. Because the data is automatically saved, you are unable to
roll back any changes.
You can start transactions in SQL Server as explicit, autocommit, or implicit
transactions. Autocommit is the default behavior; you can use implicit or explicit transaction
modes to change this default behavior.
Autocommit transactions
This is the default mode for SQL Server. Each individual Transact-SQL
statement is committed when it completes. You do not have to specify any statements to control
transactions.
Implicit transactions
As in Oracle, an implicit transaction is started whenever an INSERT,
UPDATE, DELETE, or other data manipulating function is performed. To allow implicit
transactions, use the SET IMPLICIT_TRANSACTIONS ON statement.
If this option is ON and there are no outstanding transactions, every SQL
statement automatically starts a transaction. If there is an open transaction, no new
transaction is started. The open transaction must be committed by the user explicitly with the
COMMIT TRANSACTION statement for the changes to take effect and for all locks to be
released.
Explicit transactions
An explicit transaction is a grouping of SQL statements surrounded by the
following transaction delimiters. Note that BEGIN TRANSACTION and COMMIT TRANSACTION are
required:
· BEGIN
TRANSACTION [transaction_name]
· COMMIT
TRANSACTION [transaction_name]
· ROLLBACK
TRANSACTION [transaction_name | savepoint_name]
· SAVE
TRANSACTION {savepoint_name | @savepoint_variable}
The SAVE TRANSACTION statement functions in the same way as the Oracle
SAVEPOINT command, setting a savepoint in the transaction that allows partial
rollbacks.
In the following example, the English department is changed to the Literature
department. Note the use of the BEGIN TRANSACTION and COMMIT TRANSACTION statements.
|
Oracle
|
Microsoft SQL Server
|
|
INSERT INTO DEPT_ADMIN.DEPT (DEPT, DNAME)
VALUES ('LIT', 'Literature')
/
UPDATE DEPT_ADMIN.CLASS
SET MAJOR = 'LIT'
WHERE MAJOR = 'ENG'
/
UPDATE STUDENT_ADMIN.STUDENT
SET MAJOR = 'LIT'
WHERE MAJOR = 'ENG'
/
DELETE FROM DEPT_ADMIN.DEPT
WHERE DEPT = 'ENG'
/
COMMIT
/
|
BEGIN TRANSACTION
INSERT INTO DEPT_ADMIN.DEPT (DEPT, DNAME)
VALUES ('LIT', 'Literature')
UPDATE DEPT_ADMIN.CLASS
SET DEPT = 'LIT'
WHERE DEPT = 'ENG'
UPDATE STUDENT_ADMIN.STUDENT
SET MAJOR = 'LIT'
WHERE MAJOR = 'ENG'
DELETE FROM DEPT_ADMIN.DEPT
WHERE DEPT = 'ENG'
COMMIT TRANSACTION
GO
|
Transactions can be nested one within another. If this occurs, the outermost
pair creates and commits the transaction, and the inner pairs track the nesting level. When a
nested transaction is encountered, the @@TRANCOUNT function is incremented. Usually, this
apparent transaction nesting occurs as stored procedures or triggers with BEGIN…COMMIT
pairs calling each other. Although transactions can be nested, they have little effect on the
behavior of ROLLBACK TRANSACTION statements.
In stored procedures and triggers, the number of BEGIN TRANSACTION statements
must match the number of COMMIT TRANSACTION statements. A stored procedure or trigger that
contains unpaired BEGIN TRANSACTION and COMMIT TRANSACTION statements produces an error message
when executed. The syntax allows stored procedures and triggers to be called from within
transactions if they contain BEGIN TRANSACTION and COMMIT TRANSACTION statements.
Wherever possible, break large transactions into smaller transactions. Make
sure each transaction is well defined within a single batch. To minimize possible concurrency
conflicts, transactions should not span multiple batches nor wait for user input. Grouping many
Transact‑SQL statements into one long-running transaction can negatively affect recovery
time and cause concurrency problems.
When programming with ODBC, you can select either the implicit or explicit
transaction mode by using the SQLSetConnectOption function. An ODBC
program's selection of one or the other depends on the AUTOCOMMIT connect option. If AUTOCOMMIT
is ON (the default), you are in explicit mode. If AUTOCOMMIT is OFF, you are in implicit
mode.
If you are issuing a script through SQL Query Analyzer or other query tools,
you can either include the explicit BEGIN TRANSACTION statement shown previously, or start the
script with the SET IMPLICIT_TRANSACTIONS ON statement. The BEGIN TRANSACTION approach is more
flexible, and the implicit approach is more compatible with Oracle.
One of the key functions of a database management system (DBMS) is to ensure
that multiple users can read and write records in the database without reading inconsistent
sets of records due to in-progress changes and without overwriting each other's changes
inadvertently. Oracle and SQL Server approach this task with different locking and isolation
strategies. You must consider these differences when you convert an application from Oracle to
SQL Server or the resulting application may scale poorly to high numbers of users.
Oracle uses a multiversion consistency model for all SQL statements that read
data, either explicitly or implicitly. In this model, data readers, by default, neither acquire
locks nor wait for other locks to be released before reading rows of data. When a reader
requests data that has been changed but not yet committed by other writers, Oracle re-creates
the old data by using its rollback segments to reconstruct a snapshot of rows.
Data writers in Oracle request locks on data that is updated, deleted, or
inserted. These locks are held until the end of a transaction, and they prevent other users
from overwriting uncommitted changes.
SQL Server, in contrast, uses shared locks to ensure that data readers only see
committed data. These readers take and release shared locks as they read data. These shared
locks do not affect other readers. A reader waits for a writer to commit the changes before
reading a record. A reader holding shared locks also blocks a writer trying to update the same
data.
Releasing locks quickly for applications that support high numbers of users is
more important in SQL Server than in Oracle. Releasing locks quickly is usually a matter of
keeping transactions short. If possible, a transaction should neither span multiple round-trips
to the server nor wait for the user to respond. You also need to code your application to fetch
data as quickly as possible because unfetched data scans can hold share locks at the server and
thus block updaters.
SQL Server uses a dynamic locking strategy to determine the most cost-effective
locks. SQL Server automatically determines what locks are most appropriate when the query is
executed, based on the characteristics of the schema and query. For example, to reduce the
overhead of locking, the optimizer may choose page-level locks in an index when performing an
index scan. Dynamic locking has the following advantages:
·
Simplified database administration, because database administrators no longer have to be
concerned with adjusting lock escalation thresholds.
·
Increased performance, because SQL Server minimizes system overhead by using locks appropriate
to the task.
·
Application developers can concentrate on development, because SQL Server automatically adjusts
locking.
Oracle's inability to escalate row-level locks can cause problems in queries
that include the FOR UPDATE clause and in UPDATE statements that request many rows. For
example, assume that the STUDENT table has 100,000 rows, and an
Oracle user issues the following statement (note that 100,000 rows are affected):
UPDATE STUDENT set (col) = (value);
The Oracle RDBMS locks every row in the STUDENT
table, one row at a time; this can take quite a while, and can require many system resources.
Oracle does not escalate the request to lock the entire table.
The same statement in SQL Server causes the (default) row-level locks to
escalate to a table-level lock, which is both efficient and fast.
Both Microsoft SQL Server and Oracle use the same default transaction isolation
level: READ COMMITTED. Both databases also allow the developer to request nondefault locking
and isolation behavior. In Oracle, the most common mechanisms for this are the FOR UPDATE
clause on a SELECT command, the SET TRANSACTION READ ONLY command, and the explicit LOCK TABLE
command.
Because their locking and isolation strategies are so different, it is
difficult to map these locking options directly between Oracle and SQL Server. To obtain a
better understanding of this process, it is important to understand the options that SQL Server
provides for changing its default locking behavior.
In SQL Server, the most common mechanisms for changing default locking behavior
are the SET TRANSACTION ISOLATION LEVEL statement and the locking hints that are supported in
the SELECT and UPDATE statements. The SET TRANSACTION ISOLATION LEVEL statement sets
transaction isolation levels for the duration of a user's session. This becomes the default
behavior for the session unless a locking hint is specified at the table level in the FROM
clause of an SQL statement. The transaction isolation is set like this:
SET TRANSACTION ISOLATION LEVEL
{
READ COMMITTED
| READ UNCOMMITTED
| REPEATABLE READ
| SERIALIZABLE
}
READ COMMITTED
This option is the SQL Server default. Shared locks are held while the
data is being read to avoid, but the data can be changed before the end of the transaction,
resulting in or data.
READ UNCOMMITTED
Implements dirty read, or isolation level 0 locking, which means that no
shared locks are issued and no exclusive locks are honored. When this option is set, it is
possible to read uncommitted or dirty data; values in the data can be changed and rows can
appear or disappear in the data set before the end of the transaction. This option has the same
effect as setting NOLOCK on all tables in all SELECT statements in a transaction. This is the
least restrictive of the four isolation levels.
REPEATABLE READ
Locks are placed on all data that is used in a query, preventing other
users from updating the data, but new phantom rows can be inserted into the data set by another
user and are included in later reads in the current transaction. Because concurrency is lower
than the default isolation level, use this option only when necessary.
SERIALIZABLE
A range lock is placed on the data set preventing other users from
updating or inserting rows into the data set until the transaction is complete. This is the
most restrictive of the four isolation levels. Because concurrency is lower, use this option
only when necessary. This option has the same effect as setting HOLDLOCK on all tables in all
SELECT statements in a transaction.
SQL Server implements all four SQL-92 standard transaction isolation levels;
Oracle only implements READ COMMITTED (the default) and SERIALIZABLE.
SQL Server does not directly support the non-SQL-92 standard READ ONLY
transaction isolation level offered by Oracle. If a transaction in an application requires
repeatable read behavior, you may need to use the SERIALIZABLE isolation level offered by SQL
Server. If all of the database access is read only, you can improve performance by setting the
SQL Server database option to READ ONLY.
The SELECT…FOR UPDATE statement in Oracle is used when an application
needs to issue a positioned update or delete on a cursor using the WHERE CURRENT OF syntax. In
this case, optionally remove the FOR UPDATE clause; SQL Server cursors are updatable by
default.
SQL Server cursors usually do not hold locks under the fetched row. Rather,
they use an optimistic concurrency strategy to prevent updates from overwriting each other. If
one user attempts to update or delete a row that has been changed since it was read into the
cursor, SQL Server detects the problem and issues an error message. The application can trap
this error message and retry the update or delete as appropriate.
The optimistic technique supports higher concurrency in the normal case where
conflicts between updaters are rare. If your application really needs to ensure that a row
cannot be changed after it is fetched, you can use the UPDLOCK hint in your SELECT statement to
achieve this effect.
This hint does not block other readers, but it prevents any other potential
writers from also obtaining an update lock on the data. When using ODBC, you can also achieve a
similar effect using SQLSETSTMTOPTION (…,SQL_CONCURRENCY)= SQL_CONCUR_LOCK. Either of
these options reduces concurrency.
Microsoft SQL Server can provide the same table-locking functionality as
Oracle.
|
Functionality
|
Oracle
|
Microsoft SQL Server
|
|
Lock an entire table-allows others to read a table, but prevent them from
updating it. By default, the lock is held until the end of the statement.
|
LOCK TABLE…IN SHARE MODE
|
SELECT…table_name (TABLOCK)
|
|
Lock the table until the end of the transaction
|
|
SELECT…table_name (TABLOCK
REPEATABLEREAD)
|
|
Exclusive lock -prevent others from reading or updating the table and is
held until the end of the command or transaction
|
LOCK TABLE…IN EXCLUSIVE MODE
|
SELECT…table_name (TABLOCKX)
|
|
Specify the number of milliseconds a statement waits for a lock to be
released.
|
NOWAIT works like "LOCK_TIMEOUT 0"
|
LOCK_TIMEOUT
|
A deadlock occurs when one process locks a resource needed by another process,
and the second process locks a page the first process needs. SQL Server automatically detects
and resolves deadlocks. If a deadlock is found, the server terminates the user process that has
completed the deadly embrace.
After every data modification, your program code should check for message
number 1205, which indicates a deadlock. If this message number is returned, a deadlock has
occurred and the transaction was rolled back. In this situation, your application must restart
the transaction.
Deadlocks can usually be avoided by using a few simple techniques:
·
Access tables in the same order in all parts of your application.
·
Use a clustered index on a value that will ensure that each user and/or process is inserting to
a different page in the table.
·
Keep transactions short.
For more information, search for the Microsoft Knowledge Base article
"Detecting and Avoiding Deadlocks in Microsoft SQL Server" at http://support.microsoft.com/.
To perform remote transactions in Oracle, you must have access to a remote
database node with a database link. In SQL Server, you must have access to a remote server. A remote server is a server running SQL Server on the network
that users can access by using their local server. When a server is set up as a remote server,
users can use the system procedures and the stored procedures on it without explicitly logging
in to it.
Remote servers are set up in pairs. You must configure both servers to
recognize each other as remote servers. The name of each server must be added to its partner
with the sp_addlinkedserver system stored procedure or SQL Server
Enterprise Manager.
After you set up a remote server, use the sp_addremotelogin system stored procedure or SQL Server Enterprise Manager to set
up remote login IDs for the users who must access that remote server. After this step is
completed, you must grant permissions to execute the stored procedures.
The EXECUTE statement is then used to run procedures on the remote server. This
example executes the validate_student stored procedure on the remote
server STUDSVR1 and stores the return status indicating success or
failure in @retvalue1:
DECLARE @retvalue1 int
EXECUTE @retvalue = STUDSVR1.student_db.student_admin.validate_student '111111111'
For more information, see SQL Server 2000 Books Online.
Oracle automatically initiates a distributed transaction if changes are made to
tables in two or more networked database nodes. SQL Server distributed transactions use the
two-phase commit services of the Microsoft Distributed Transaction Coordinator (MS DTC)
included with SQL Server.
By default, SQL Server must be instructed to participate in a distributed
transaction. SQL Server participation in an MS DTC transaction can be started by either of the
following:
·
The BEGIN DISTRIBUTED TRANSACTION statement. This statement begins a new MS DTC
transaction.
· A
client application calling MS DTC transaction interfaces directly.
In the example, notice the distributed update to both the local table
GRADE and the remote table CLASS (using a
class_name procedure):
BEGIN DISTRIBUTED TRANSACTION
UPDATE STUDENT_ADMIN.GRADE
SET GRADE = 'B+' WHERE SSN = '111111111' AND CCODE = '1234'
DECLARE @retvalue1 int
EXECUTE @retvalue1 = CLASS_SVR1.dept_db.dept_admin.class_name '1234', 'Basketweaving'
COMMIT TRANSACTION
GO
If the application cannot complete the transaction, the application program
cancels it by using the ROLLBACK TRANSACTION statement. If the application fails or a
participating resource manager fails, MS DTC cancels the transaction. MS DTC does not support
distributed savepoints or the SAVE TRANSACTION statement. If an MS DTC transaction is
terminated or rolled back, the entire transaction is rolled back to the beginning of the
distributed transaction, regardless of any savepoints.
The Oracle and MS DTC two-phase commit mechanisms are similar in operation. In
the first phase of a SQL Server two-phase commit, the transaction manager requests each
enlisted resource manager to prepare to commit. If any resource manager cannot prepare, the
transaction manager broadcasts an abort decision to everyone involved in the transaction.
If all resource managers can successfully prepare, the transaction manager
broadcasts the commit decision. This is the second phase of the commit process. While a
resource manager is prepared, it is in doubt about whether the transaction is committed or
terminated. MS DTC keeps a sequential log so that its commit or terminate decisions are
durable. If a resource manager or transaction manager fails, they reconcile in-doubt
transactions when they reconnect.
This section outlines the
similarities and differences between Transact‑SQL and PL/SQL language syntax and presents
conversion strategies.
Use the following guidelines when migrating your Oracle DML statements and
PL/SQL programs to SQL Server.
1. Verify that the syntax of
all SELECT, INSERT, UPDATE, and DELETE statements is valid. Make any required
modifications.
2. Change all outer joins to
SQL-92 standard outer join syntax.
3. Replace Oracle functions
with the appropriate SQL Server functions.
4. Check all comparison
operators.
5. Replace the "||" string
concatenation operator with the "+" string concatenation operator.
6. Replace PL/SQL programs
with Transact-SQL programs.
7. Change all PL/SQL cursors
to either noncursor SELECT statements or Transact‑SQL cursors.
8. Replace PL/SQL procedures,
functions, and packages with Transact‑SQL procedures.
9. Convert PL/SQL triggers to
Transact‑SQL triggers.
10. Use
the SET SHOWPLAN statement to tune your queries for performance.
The SELECT statement syntax used by Oracle and Microsoft SQL Server is
similar.
|
Oracle
|
Microsoft SQL Server
|
|
SELECT [/*+ optimizer_hints*/]
[ALL | DISTINCT] select_list
[FROM
{table_name | view_name |
select_statement}]
[WHERE clause]
[GROUP BY group_by_expression]
[HAVING search_condition]
[START WITH … CONNECT BY]
[{UNION | UNION ALL | INTERSECT |
MINUS} SELECT …]
[ORDER BY clause]
[FOR UPDATE]
|
SELECT select_list
[INTO new_table_]
FROM table_source
[WHERE search_condition]
[ GROUP BY [ALL] group_by_expression [,…n]
[ WITH { CUBE | ROLLUP } ]
[HAVING search_condition]
[ORDER BY order_expression [ASC | DESC] ]
In addition:
UNION operator
COMPUTE clause
FOR BROWSE clause
OPTION clause
|
Oracle-specific cost-based optimizer hints are not supported by SQL Server, and
must be removed. The recommended technique is to use SQL Server cost-based optimization. For
more information, see "Tuning SQL Statements" in this paper.
SQL Server does not support the Oracle START WITH…CONNECT BY clause. You
can replace this in SQL Server by creating a stored procedure that performs the same task. For
more information, see "Expanding Hierarchies" in SQL Server 2000 Books Online, or search the
Microsoft Knowledge Base for relevant articles at http://support.microsoft.com/.
The Oracle INTERSECT and MINUS set operators are not supported by SQL Server.
The SQL Server EXISTS and NOT EXISTS clauses can be used to accomplish the same result.
The following example uses the INTERSECT operator to find the course code and
course name for all classes that have students. Notice how the EXISTS operator replaces the use
of the INTERSECT operator. The data that is returned is identical.
|
Oracle
|
Microsoft SQL Server
|
|
SELECT CCODE, CNAME
FROM DEPT_ADMIN.CLASS
INTERSECT
SELECT C.CCODE, C.CNAME
FROM STUDENT_ADMIN.GRADE G,
DEPT_ADMIN.CLASS C
WHERE C.CCODE = G.CCODE
|
SELECT CCODE, CNAME
FROM DEPT_ADMIN.CLASS C
WHERE EXISTS
(SELECT 'X' FROM
STUDENT_ADMIN.GRADE
G
WHERE C.CCODE = G.CCODE)
|
This example uses the MINUS operator to find those classes that do not have any
students.
|
Oracle
|
Microsoft SQL Server
|
|
SELECT CCODE, CNAME
FROM DEPT_ADMIN.CLASS
MINUS
SELECT C.CCODE, C.CNAME
FROM STUDENT_ADMIN.GRADE G,
DEPT_ADMIN.CLASS C
WHERE C.CCODE = G.CCODE
|
SELECT CCODE, CNAME
FROM DEPT_ADMIN.CLASSC
WHERE NOT EXISTS
(SELECT 'X' FROM
STUDENT_ADMIN.GRADE
G
WHERE C.CCODE = G.CCODE)
|
The INSERT statement syntax used by Oracle and Microsoft SQL Server is
similar.
|
Oracle
|
Microsoft SQL Server
|
|
INSERT INTO
{table_name | view_name | select_statement} [(column_list)]
{values_list | select_statement}
|
INSERT [INTO]
{
table_name [ [AS] table_alias] WITH ( <table_hint_limited> […n])
| view_name [ [AS] table_alias]
| rowset_function_limited
}
{ [(column_list)]
{ VALUES (
{ DEFAULT
| NULL
| expression
}[,…n]
)
| derived_table
| execute_statement
}
}
| DEFAULT VALUES
|
The Transact‑SQL language supports inserts into tables and views, but
does not support insert operations into SELECT statements. If your Oracle application code
performs inserts into SELECT statements, this must be changed.
|
Oracle
|
Microsoft SQL Server
|
|
INSERT INTO (SELECT SSN, CCODE,
GRADE FROM GRADE)
VALUES ('111111111', '1111',NULL)
|
INSERT INTO GRADE (SSN, CCODE, GRADE)
VALUES ('111111111', '1111',NULL)
|
The Transact‑SQL values_list parameter offers
the SQL-92 standard keyword DEFAULT, which is not supported by Oracle. This keyword specifies
that the default value for the column be used when an insert is performed. If a default value
does not exist for the specified column, a NULL is inserted. If the column does not allow
NULLs, an error message is returned. If the column is defined as a timestamp data type, the next sequential value is inserted.
The DEFAULT keyword cannot be used with an identity column. To generate the
next sequential number, columns with the IDENTITY property must not be listed in the
column_list or values_clause. You do
not have to use the DEFAULT keyword to obtain the default value for a column. As in Oracle, if
the column is not referenced in the column_list and it has a
default value, the default value is placed in the column. This is the most compatible approach
to use when performing the migration.
One useful Transact‑SQL option (EXECute procedure_name) is to execute a procedure and pipe its output into a target
table or view. Oracle does not allow this.
Because Transact‑SQL supports most of the syntax used by the Oracle
UPDATE command, minimal revision is required.
|
Oracle
|
Microsoft SQL Server
|
|
UPDATE
{table_name | view_name |
select_statement}
SET [column_name(s) = {constant_value | expression | select_statement | column_list |
variable_list]
{where_statement}
|
UPDATE
{
table_name [ [AS] table_alias] WITH (
<table_hint_limited> […n])
| view_name [ [AS] table_alias]
| rowset_function_limited
}
SET
{column_name
= {expression | DEFAULT | NULL}
| @variable =
expression
| @variable =
column = expression }
[,…n]
{{[FROM {<table_source>} [, …n] ]
[WHERE
<search_condition>]
}
|
[WHERE CURRENT OF
{ { [GLOBAL] cursor_name } | cursor_variable_name}
] }
[OPTION (<query_hint>
[,…n] )]
|
The Transact‑SQL UPDATE statement does not support update operations
against SELECT statements. If your Oracle application code performs updates against SELECT
statements, you can turn the SELECT statement into a view, and then use the view name in the
SQL Server UPDATE statement. See the example shown previously in "INSERT Statements."
The Oracle UPDATE command can use only program variables from within a PL/SQL
block. The Transact‑SQL language does not require the use of blocks to use variables.
|
Oracle
|
Microsoft SQL Server
|
|
DECLARE
VAR1 NUMBER(10,2);
BEGIN
VAR1 := 2500;
UPDATE STUDENT_ADMIN.STUDENT
SET TUITION_TOTAL = VAR1;
END;
|
DECLARE
@VAR1 NUMERIC(10,2)
SELECT @VAR1 = 2500
UPDATE STUDENT_ADMIN.STUDENT
SET TUITION_TOTAL=@VAR1
|
The keyword DEFAULT can be used to set a column to its default value in SQL
Server. You cannot set a column to a default value with the Oracle UPDATE command.
Transact‑SQL and Oracle SQL support the use of subqueries in an UPDATE
statement. However, the Transact‑SQL FROM clause can be used to create an UPDATE based on
a join. This capability makes your UPDATE syntax more readable and in some cases can improve
performance.
|
Oracle
|
Microsoft SQL Server
|
|
UPDATE STUDENT_ADMIN.STUDENT S
SET TUITION_TOTAL = 1500
WHERE SSN IN (SELECT SSN
FROM GRADE G
WHERE G.SSN = S.SSN
AND G.CCODE = '1234')
|
Subquery:
UPDATE STUDENT_ADMIN.STUDENT S
SET TUITION_TOTAL = 1500
WHERE SSN IN (SELECT SSN
FROM GRADE G
WHERE G.SSN = S.SSN
AND G.CCODE = '1234')
FROM clause:
UPDATE STUDENT_ADMIN.STUDENT S
SET TUITION_TOTAL = 1500
FROM GRADE G
WHERE S.SSN = G.SSN
AND G.CCODE = '1234'
|
In most cases, you do not need to modify DELETE statements. If you perform
deletes against SELECT statements in Oracle, you must modify the syntax for SQL Server, because
Transact‑SQL does not support this functionality.
Transact‑SQL supports the use of subqueries in the WHERE clause, as well
as joins in the FROM clause. The latter can produce more efficient statements. See the example
shown previously in "UPDATE Statements."
|
Oracle
|
Microsoft SQL Server
|
|
DELETE [FROM]
{table_name | view_name |
select_statement}
[WHERE clause]
|
DELETE
[FROM ]
{
table_name [ [AS] table_alias] WITH (
<table_hint_limited> […n])
| view_name [ [AS] table_alias]
| rowset_function_limited
}
[ FROM {<table_source>} [,
…n] ]
[WHERE
{ <search_condition>
| { [ CURRENT
OF
{
{
[ GLOBAL ] cursor_name }
|
cursor_variable_name
}
]
}
]
[OPTION (<query_hint> [,…n])]
|
The TRUNCATE TABLE syntax used by Oracle and Microsoft SQL Server is similar.
TRUNCATE TABLE is used to remove all of the rows from a table. The table structure and all of
its indexes continue to exist. Unlike the DELETE statement, which explicitly deletes each
record of a table, TRUNCATE TABLE removes the data from the table by deallocating the data
pages of the table and logging these deallocations in the transaction log. Because the rows are
not explicitly deleted, DELETE triggers are not executed. If a table is referenced by a FOREIGN
KEY constraint, it cannot be truncated.
|
Oracle
|
Microsoft SQL Server
|
|
TRUNCATE TABLE table_name
[{DROP | REUSE} STORAGE]
|
TRUNCATE TABLE table_name
|
In SQL Server, only the table owner can issue this statement. In Oracle, this
command can be issued if you are the table owner or have the DELETE TABLE system privilege.
The Oracle TRUNCATE TABLE command can optionally release the storage space
occupied by the rows in the table. The SQL Server TRUNCATE TABLE statement always reclaims
space occupied by the table data and its associated indexes.
Oracle sequences are database objects that are not directly related to any
given table or column. The relationship between a column and a sequence is implemented in the
application, by assigning the sequence value to a column programmatically. Therefore, Oracle
does not enforce any rules when it works with sequences. However, in Microsoft SQL Server
identity columns, values cannot be updated and the DEFAULT keyword cannot be used.
By default, data cannot be inserted directly into an identity column. The
identity column automatically generates a unique, sequential number for each new row inserted
in the table. This default can be overridden using the following SET statement:
SET IDENTITY_INSERT table_name ON
With IDENTITY_INSERT set to ON, the user can insert any value into the identity
column of a new row. To prevent the entry of duplicate numbers, a unique index must be created
against the column. The purpose of this statement is to allow a user to re-create a value for a
row that has been deleted accidentally. The @@IDENTITY function can be used to obtain the last
identity value.
The TRUNCATE TABLE statement resets an identity column to its original SEED
value. If you do not want to reset the identity value for a column, use the DELETE statement
without a WHERE clause instead of the TRUNCATE TABLE statement. You will have to evaluate how
this affects your Oracle migration, because ORACLE SEQUENCES are not reset following the
TRUNCATE TABLE command.
You can perform only inserts or deletes when working with timestamp columns. If you attempt to update a timestamp
column, you receive this error message:
Msg 272, Level 16, State 1 Can't update a TIMESTAMP column.
Oracle uses the FOR UPDATE clause to lock rows specified in the SELECT command.
You do not need to use the equivalent clause in Microsoft SQL Server because this is the
default behavior.
The SQL Server COMPUTE clause is used to generate row aggregate functions (SUM,
AVG, MIN, MAX, and COUNT), which appear as additional rows in the query results. The COMPUTE
clause allows you to see detail and summary rows in one set of results. You can calculate
summary values for subgroups, and you can calculate more than one aggregate function for the
same group.
The Oracle SELECT command syntax does not support the COMPUTE clause.
Nevertheless, the SQL Server COMPUTE clause works just like the COMPUTE command found in the
Oracle SQL*Plus query tool.
Microsoft SQL Server 2000 allows up to 256 tables to be joined in a join
clause, including both temporary and permanent tables. There is no join limit in Oracle.
When using outer joins in Oracle, the outer join operator (+) is placed
typically next to the child (foreign key) column in the join. The (+) returns rows from the
child table even if there is no match with the parent table. If the foreign key allows null
values, the (+) can be placed on the parent (PRIMARY KEY or UNIQUE constraint) column. You
cannot place the (+) on both sides of the equal sign (=).
With SQL Server, you can use the *= and =* outer join operators. The * is used
to identify the column that has unmatched values that should also be included in the result
set. If the child (foreign key) column does not allow null values, the * is placed on the
parent (PRIMARY KEY or UNIQUE constraint) column side of the equal sign. The placement of the *
is essentially reversed in Oracle. You cannot place the * on both sides of the equal sign
(=).
The *= and =* are considered legacy join operators. SQL Server also supports
the SQL-92 standard join operators listed below. It is recommended that you use this syntax.
The SQL-92 standard syntax is more powerful and has fewer restrictions than the * operators.
|
Join operation
|
Description
|
|
CROSS JOIN
|
This is the cross product of two tables. It returns the same rows as if
no WHERE clause was specified in an old-style join. This type of join is called a
Cartesian-join in Oracle.
|
|
INNER
|
This join specifies that all inner rows be returned. Any unmatched rows
are discarded. This is identical to a standard Oracle table join.
|
|
LEFT [OUTER]
|
This type of join specifies that all of the left table outer rows be
returned, even if no column matches are found. This operates just like an Oracle outer
join (+).
|
|
RIGHT [OUTER]
|
This type of join specifies that all of the right table outer rows be
returned, even if no column matches are found. This operates just like an Oracle outer
join (+).
|
|
FULL [OUTER]
|
If a row from either table does not match the selection criteria, this
specifies the row be included in the result set and its output columns that correspond to
the other table be set to NULL. This would be the same as placing the Oracle outer join
operator on both sides of the "=" sign (col1(+) = col2(+)), which is not allowed.
|
The following code examples return lists of classes taken by all students.
Outer joins are defined between the student and grade tables that allow all students to appear,
even those who are not enrolled in any classes. Outer joins are also added to the class table
in order to return the class names. If outer joins are not added to the class tables, those
students who are not enrolled in any classes are not returned because they have null course
codes (CCODE).
|
Oracle
|
Microsoft SQL Server
|
|
SELECT S.SSN AS SSN,
FNAME, LNAME
FROM STUDENT_ADMIN.STUDENT S,
DEPT_ADMIN.CLASS C,
STUDENT_ADMIN.GRADE G
WHERE S.SSN = G.SSN(+)
AND G.CCODE = C.CCODE(+)
|
SELECT S.SSN AS SSN,
FNAME, LNAME
FROM STUDENT_ADMIN.GRADE G
RIGHT OUTER JOIN
STUDENT_ADMIN.STUDENT S
ON G.SSN = S.SSN
LEFT OUTER JOIN
DEPT_ADMIN.CLASS C
ON G.CCODE = C.CCODE
|
Microsoft SQL Server and Oracle support the use of SELECT statements as the
source of tables when performing queries. SQL Server requires an alias; the use of an alias is
optional with Oracle.
|
Oracle
|
Microsoft SQL Server
|
|
SELECT SSN, LNAME, FNAME,
TUITION_PAID, SUM_PAID
FROM STUDENT_ADMIN.STUDENT,
(SELECT SUM(TUITION_PAID) SUM_PAID
FROM STUDENT_ADMIN.STUDENT)
|
SELECT SSN, LNAME, FNAME,
TUITION_PAID, SUM_PAID
FROM STUDENT_ADMIN.STUDENT,
(SELECT SUM(TUITION_PAID) SUM_PAID
FROM STUDENT_ADMIN.STUDENT) SUM_STUDENT
|
Microsoft SQL Server implements binary large objects (BLOBs) with text and image columns. Oracle implements BLOBs with
LONG and LONG RAW columns. In Oracle, a SELECT command can query the values in LONG and LONG
RAW columns.
In SQL Server, you can use a standard Transact‑SQL statement or the
specialized READTEXT statement to read data in text and image columns. The READTEXT statement allows you to read partial sections of a
text or image column. Oracle does not
provide an equivalent statement for working with LONG and LONG RAW columns.
The READTEXT statement makes use of a text_pointer,
which can be obtained using the TEXTPTR function. The TEXTPTR function returns a pointer to the
text or image column in the specified row
or to the text or image column in the last
row returned by the query if more than one row is returned. Because the TEXTPTR function
returns a 16-byte binary string, it is best to declare a local variable to hold the text
pointer, and then use the variable with READTEXT.
The READTEXT statement specifies how many bytes to return. The value in the
@@TEXTSIZE function, which is the limit on the number of characters or bytes to be returned,
supersedes the size specified by the READTEXT statement if it is less than the specified size
for READTEXT.
The SET statement can be used with the TEXTSIZE parameter to specify the size,
in bytes, of text data to be returned with a SELECT statement. If you specify a TEXTSIZE of 0,
the size is reset to the default (4 KB). Setting the TEXTSIZE parameter affects the @@TEXTSIZE
function. The SQL Server ODBC driver automatically sets the TEXTSIZE parameter when the
SQL_MAX_LENGTH statement option is changed.
In Oracle, UPDATE and INSERT commands are used to change values in LONG and
LONG RAW columns. In SQL Server, you can use standard UPDATE and INSERT statements, or you can
use the UPDATETEXT and WRITETEXT statements. Both UPDATETEXT and WRITETEXT allow a nonlogged
option, and UPDATETEXT allows for partial updating of a text or
image column.
The UPDATETEXT statement can be used to replace existing data, delete existing
data, or insert new data. Newly inserted data can be a constant value, table name, column name,
or text pointer.
The WRITETEXT statement completely overwrites any existing data in the column
it affects. Use WRITETEXT to replace text data and UPDATETEXT to modify text data. The
UPDATETEXT statement is more flexible because it changes only a portion of a text of image
value rather than the entire value.
For more information, see SQL Server 2000 Books Online.
The tables in this section show the relationship between Oracle and SQL Server
scalar-valued and aggregate functions. Although the names appear to be the same, the functions
vary in numbers and types of arguments. Also, functions that are supplied only by Microsoft SQL
Server are not mentioned in this list because this paper is limited to easing migration from
existing Oracle applications. Examples of functions not supported by Oracle are: degrees
(DEGREES), PI (PI), and random number (RAND).
The following are number/mathematical functions supported by Oracle and their
Microsoft SQL Server equivalents.
|
Function
|
Oracle
|
Microsoft SQL Server
|
|
Absolute value
|
ABS
|
Same
|
|
Arc cosine
|
ACOS
|
Same
|
|
Arc sine
|
ASIN
|
Same
|
|
Arc tangent of n
|
ATAN
|
Same
|
|
Arc tangent of n and m
|
ATAN2
|
ATN2
|
|
Smallest integer >= value
|
CEIL
|
CEILING
|
|
Cosine
|
COS
|
Same
|
|
Hyperbolic cosine
|
COSH
|
COT
|
|
Exponential value
|
EXP
|
Same
|
|
Largest integer <= value
|
FLOOR
|
Same
|
|
Natural logarithm
|
LN
|
LOG
|
|
Logarithm, any base
|
LOG(N)
|
N/A
|
|
Logarithm, base 10
|
LOG(10)
|
LOG10
|
|
Modulus (remainder)
|
MOD
|
USE MODULO (%) OPERATOR
|
|
Power
|
POWER
|
Same
|
|
Random number
|
N/A
|
RAND
|
|
Round
|
ROUND
|
Same
|
|
Function (continued)
|
Oracle (continued)
|
Microsoft SQL Server (continued)
|
|
Sign of number
|
SIGN
|
Same
|
|
Sine
|
SIN
|
Same
|
|
Hyperbolic sine
|
SINH
|
N/A
|
|
Square root
|
SQRT
|
Same
|
|
Tangent
|
TAN
|
Same
|
|
Hyperbolic tangent
|
TANH
|
N/A
|
|
Truncate
|
TRUNC
|
N/A
|
|
Largest number in list
|
GREATEST
|
N/A
|
|
Smallest number in list
|
LEAST
|
N/A
|
|
Convert number if NULL
|
NVL
|
ISNULL
|
The following are character functions supported by Oracle and their Microsoft
SQL Server equivalents.
|
Function
|
Oracle
|
Microsoft SQL Server
|
|
Convert character to ASCII
|
ASCII
|
Same
|
|
String concatenate
|
CONCAT
|
(expression + expression)
|
|
Convert ASCII to character
|
CHR
|
CHAR
|
|
Return starting point of character in character string (from left)
|
INSTR
|
CHARINDEX
|
|
Convert characters to lowercase (LOWER)
|
LOWER
|
Same
|
|
Convert characters to uppercase (UPPER)
|
UPPER
|
Same
|
|
Pad left side of character string
|
LPAD
|
N/A
|
|
Remove leading blanks
|
LTRIM
|
Same
|
|
Remove trailing blanks
|
RTRIM
|
Same
|
|
Function (continued)
|
Oracle (continued)
|
Microsoft SQL Server (continued)
|
|
Starting point of pattern in character string
|
INSTR
|
PATINDEX
|
|
Repeat character string multiple times
|
RPAD
|
REPLICATE
|
|
Phonetic representation of character string
|
SOUNDEX
|
Same
|
|
String of repeated spaces
|
RPAD
|
SPACE
|
|
Character data converted from numeric data
|
TO_CHAR
|
STR
|
|
Substring
|
SUBSTR
|
SUBSTRING
|
|
Replace characters
|
REPLACE
|
STUFF
|
|
Capitalize first letter of each word in string
|
INITCAP
|
N/A
|
|
Translate character string
|
TRANSLATE
|
N/A
|
|
Length of character string
|
LENGTH
|
DATALENGTH or LEN
|
|
Greatest character string in list
|
GREATEST
|
N/A
|
|
Least character string in list
|
LEAST
|
N/A
|
|
Convert string if NULL
|
NVL
|
ISNULL
|
The following are date functions supported by Oracle and their Microsoft SQL
Server equivalents.
|
Function
|
Oracle
|
Microsoft SQL Server
|
|
Date addition
|
(date column +/- value) or
ADD_MONTHS
|
DATEADD
|
|
Difference between dates
|
(date column +/- value) or
MONTHS_BETWEEN
|
DATEDIFF
|
|
Current date and time
|
SYSDATE
|
GETDATE()
|
|
Last day of month
|
LAST_DAY
|
N/A
|
|
Time zone conversion
|
NEW_TIME
|
N/A
|
|
First weekday after date
|
NEXT_DAY
|
N/A
|
|
Character string representation of date
|
TO_CHAR
|
DATENAME
|
|
Integer representation of date
|
TO_NUMBER(TO_CHAR))
|
DATEPART
|
|
Date round
|
ROUND
|
CONVERT
|
|
Date truncate
|
TRUNC
|
CONVERT
|
|
Character string to date
|
TO_DATE
|
CONVERT
|
|
Convert date if NULL
|
NVL
|
ISNULL
|
The following are conversion functions supported by Oracle and their Microsoft
SQL Server equivalents.
|
Function
|
Oracle
|
Microsoft SQL Server
|
|
Number to character
|
TO_CHAR
|
CONVERT
|
|
Character to number
|
TO_NUMBER
|
CONVERT
|
|
Date to character
|
TO_CHAR
|
CONVERT
|
|
Character to date
|
TO_DATE
|
CONVERT
|
|
Hex to binary
|
HEX_TO_RAW
|
CONVERT
|
|
Binary to hex
|
RAW_TO_HEX
|
CONVERT
|
The following are other row-level functions supported by Oracle and their
Microsoft SQL Server equivalents.
|
Function
|
Oracle
|
Microsoft SQL Server
|
|
Return first nonnull expression
|
DECODE
|
COALESCE
|
|
Current sequence value
|
CURRVAL
|
N/A
|
|
Next sequence value
|
NEXTVAL
|
N/A
|
|
If exp1 = exp2, return null
|
DECODE
|
NULLIF
|
|
User's login ID number
|
UID
|
SUSER_ID
|
|
User's login name
|
USER
|
SUSER_NAME
|
|
User's database ID number
|
UID
|
USER_ID
|
|
User's database name
|
USER
|
USER_NAME
|
|
Current User
|
CURRENT_USER
|
Same
|
|
User environment (audit trail)
|
USERENV
|
N/A
|
|
Level in CONNECT BY clause
|
LEVEL
|
N/A
|
The following are aggregate functions supported by Oracle and their SQL Server
equivalents.
|
Function
|
Oracle
|
Microsoft SQL Server
|
|
Average
|
AVG
|
Same
|
|
Count
|
COUNT
|
Same
|
|
Maximum
|
MAX
|
Same
|
|
Minimum
|
MIN
|
Same
|
|
Standard deviation
|
STDDEV
|
STDEV or STDEVP
|
|
Summation
|
SUM
|
Same
|
|
Variance
|
VARIANCE
|
VAR or VARP
|
Both the Oracle DECODE statement and the Microsoft SQL Server CASE expression
perform conditional tests. When the value in test_value matches any
following expression, the related value is returned. If no match is found, the default_value is returned. If no default_value is
specified, both DECODE and CASE return NULL if there is no match. The table shows the syntax as
well as an example of a converted DECODE command.
|
Oracle
|
Microsoft SQL Server
|
|
DECODE (test_value,
expression1, value1
[[,expression2, value2]
[…]]
[,default_value]
)
CREATE VIEW STUDENT_ADMIN.STUDENT_GPA
(SSN, GPA)
AS SELECT SSN, ROUND(AVG(DECODE(grade
,'A', 4
,'A+', 4.3
,'A-', 3.7
,'B', 3
,'B+', 3.3
,'B-', 2.7
,'C', 2
,'C+', 2.3
,'C-', 1.7
,'D', 1
,'D+', 1.3
,'D-', 0.7
,0)),2)
FROM STUDENT_ADMIN.GRADE
GROUP BY SSN
|
CASE test_value
WHEN expression1 THEN value1
[[WHEN expression2 THEN value2] [...]]
[ELSE default_value]
END
CREATE VIEW STUDENT_ADMIN.STUDENT_GPA
(SSN, GPA)
AS SELECT SSN, ROUND(AVG(CASE grade
WHEN 'A' THEN 4
WHEN 'A+' THEN 4.3
WHEN 'A-' THEN 3.7
WHEN 'B' THEN 3
WHEN 'B+' THEN 3.3
WHEN 'B-' THEN 2.7
WHEN 'C' THEN 2
WHEN 'C+' THEN 2.3
WHEN 'C-' THEN 1.7
WHEN 'D' THEN 1
WHEN 'D+' THEN 1.3
WHEN 'D-' THEN 0.7
ELSE 0
END),2)
FROM STUDENT_ADMIN.GRADE
GROUP BY SSN
|
The CASE expression can support the use of SELECT statements for performing
Boolean tests, something the DECODE command does not allow. For more information about the CASE
expression, see SQL Server 2000 Books Online.
The Microsoft SQL Server CONVERT and CAST functions are multiple purpose
conversion functions. They provide similar functionality, converting an expression of one data
type to another data type, and supporting a variety of special date formats:
CAST (expression AS
data_type)
CONVERT (data
type[(length)], expression
[, style])
CAST is a SQL-92 standard function. These functions perform the same operations
as the Oracle TO_CHAR, TO_NUMBER, TO_DATE, HEXTORAW, and RAWTOHEX functions.
The data type is any system data type into which the expression is to be
converted. User-defined data types cannot be used. The length
parameter is optional and is used with char, varchar, binary, and varbinary data types. The maximum allowable length is 8000.
|
Conversion
|
Oracle
|
Microsoft SQL Server
|
|
Character to number
|
TO_NUMBER('10')
|
CONVERT(numeric, '10')
|
|
Number to character
|
TO_CHAR(10)
|
CONVERT(char, 10)
|
|
Character to date
|
TO_DATE('04-JUL-97')
TO_DATE('04-JUL-1997',
'dd-mon-yyyy')
TO_DATE('July 4, 1997',
'Month dd, yyyy')
|
CONVERT(datetime, '04-JUL-97')
CONVERT (datetime, '04-JUL-1997')
CONVERT (datetime, 'July 4, 1997')
|
|
Date to character
|
TO_CHAR(sysdate)
TO_CHAR(sysdate, 'dd mon yyyy')
TO_CHAR(sysdate, 'mm/dd/yyyy')
|
CONVERT(char, GETDATE())
CONVERT(char, GETDATE (), 106)
CONVERT(char, GETDATE (), 101)
|
|
Hex to binary
|
HEXTORAW('1F')
|
CONVERT(binary, '1F')
|
|
Binary to hex
|
RAWTOHEX(binary_column)
|
CONVERT(char,binary_column)
|
Notice how character strings are converted to dates. In Oracle, the default
date format model is "DD-MON-YY." If you use any other format, you must provide an appropriate
date format model. The CONVERT function automatically converts standard date formats without
the need for a format model.
When you convert from a date to a character string, the default output for the
CONVERT function is "dd mon yyyy hh:mm:ss:mmm(24h)". A numeric style code is used to format the
output to other types of date format models. For more information about the CONVERT function,
see SQL Server 2000 Books Online.
The following table shows the default output for Microsoft SQL Server
dates.
|
Without century
|
With century
|
Standard
|
Output
|
|
-
|
0 or 100 (*)
|
Default
|
mon dd yyyy hh:miAM (or PM)
|
|
1
|
101
|
USA
|
mm/dd/yy
|
|
2
|
102
|
ANSI
|
yy.mm.dd
|
|
3
|
103
|
British/French
|
dd/mm/yy
|
|
4
|
104
|
German
|
dd.mm.yy
|
|
5
|
105
|
Italian
|
dd-mm-yy
|
|
6
|
106
|
-
|
dd mon yy
|
|
7
|
107
|
-
|
mon dd, yy
|
|
8
|
108
|
-
|
hh:mm:ss
|
|
-
|
9 or 109 (*)
|
Default milliseconds
|
mon dd yyyy hh:mi:ss:mmm (AM or PM)
|
|
10
|
110
|
USA
|
mm-dd-yy
|
|
11
|
111
|
JAPAN
|
yy/mm/dd
|
|
12
|
112
|
ISO
|
yymmdd
|
|
-
|
13 or 113 (*)
|
Europe default
|
dd mon yyyy hh:mm:ss:mmm(24h)
|
|
14
|
114
|
-
|
hh:mi:ss:mmm(24h)
|
The syntax to create a user-defined function that returns a scalar data type is
similar between Oracle and SQL Server 2000.
|
Oracle
|
Microsoft SQL Server
|
|
SELECT ssn, fname, lname, tuition_paid,
tuition_paid/get_sum_major(major) as percent_major
FROM student_admin.student
|
SELECT ssn, fname, lname, tuition_paid, tuition_paid/sum_major as
percent_major
FROM student_admin.student,
(SELECT major, sum(tuition_paid) sum_major
FROM student_admin.student
GROUP BY major) sum_student
WHERE student.major = sum_student.major
|
|
CREATE OR REPLACE FUNCTION get_sum_major
(inmajor varchar2) RETURN NUMBER
AS sum_paid number;
BEGIN
SELECT sum(tuition_paid) into sum_paid
FROM student_admin.student
WHERE major = inmajor;
RETURN(sum_paid);
END get_sum_major;
|
CREATE FUNCTION get_sum_major (@inmajor varchar(40))
RETURNS money
AS
BEGIN
DECLARE @sum_paid money
SELECT@sum_paid = sum(tuition_paid)
FROM student_admin.student
WHERE major = @inmajor
RETURN @sum_paid
END
|
SQL Server user-defined functions also can return a table data type. These
functions can be either in-line functions, consisting of a simple SELECT statement or
multistatement functions, consisting of many statements used to build a table. Both of these
functions can accept parameters and can be accessed in the FROM clause of a Transact‑SQL
statement. These functions can provide a powerful alternative both to using stored procedures,
because their result set can be accessed directly within a Transact‑SQL statement, and to
using views because they can accept parameters to narrow down a result set.
Here is the syntax to create the user-defined function types that return
tables.
Syntax for an inline-table function
CREATE FUNCTION [ owner_name. ] function_name
( [ { @parameter_name [AS]
scalar_parameter_data_type [ = default ] } [ ,...n ] ] )
RETURNS TABLE
[ WITH <function_option > [ [,] ...n ] ]
[ AS ]
RETURN [ ( ] select-stmt [ ) ]
Syntax for a multistatement table function
CREATE FUNCTION [ owner_name. ] function_name
( [ { @parameter_name [AS]
scalar_parameter_data_type [ = default ] } [ ,...n ] ] )
RETURNS @return_variable TABLE < table_type_definition >
[ WITH < function_option > [ [,] ...n ] ]
[ AS ]
BEGIN
function_body
RETURN
END
Oracle and Microsoft SQL Server comparison operators are nearly identical.
|
Operator
|
Oracle
|
Microsoft SQL Server
|
|
Equal to
|
(=)
|
Same
|
|
Greater than
|
(>)
|
Same
|
|
Less than
|
(<)
|
Same
|
|
Greater than or equal to
|
(>=)
|
Same
|
|
Less than or equal to
|
(<=)
|
Same
|
|
Not equal to
|
(!=, <>,^=)
|
Same
|
|
Not greater than, not less than
|
N/A
|
!> , !<
|
|
In any member in set
|
IN
|
Same
|
|
Not in any member in set
|
NOT IN
|
Same
|
|
Any value in set
|
ANY, SOME
|
Same
|
|
Referring to all values in set.
|
!= ALL, <> ALL, < ALL, > ALL, <= ALL, >= ALL
|
Same
|
|
Like pattern
|
LIKE
|
Same
|
|
Not like pattern
|
NOT LIKE
|
Same
|
|
Value between x and y
|
BETWEEN x AND y
|
Same
|
|
Value not between
|
NOT BETWEEN
|
Same
|
|
Value exists
|
EXISTS
|
Same
|
|
Value does not exist
|
NOT EXISTS
|
Same
|
|
Value {is | is not} NULL
|
IS NULL, IS NOT NULL
|
Same. Also supports = NULL, != NULL for backward compatibility (not
recommended).
|
The SQL Server LIKE keyword offers useful wildcard search options that are not
supported by Oracle. In addition to supporting the % and _ wildcard characters common to both
RDBMSs, the [ ] and [^] characters are also supported by SQL Server.
The [ ] character set is used to search for any single character within a
specified range. For example, if you search for the characters a through f in a single
character position, you can specify this with LIKE '[a-f]' or LIKE '[abcdef]'. The usefulness
of these additional wildcard characters is shown in this table.
|
Oracle
|
Microsoft SQL Server
|
|
SELECT * FROM STUDENT_ADMIN.STUDENT
WHERE LNAME LIKE 'A%'
OR LNAME LIKE 'B%'
OR LNAME LIKE 'C%'
|
SELECT * FROM STUDENT_ADMIN.STUDENT
WHERE LNAME LIKE '[ABC]%'
|
The [^] wildcard character set is used to specify characters NOT in the
specified range. For example, if any character except a through f is acceptable, you use LIKE
'[^a - f]' or LIKE '[^abcdef]'.
For more information about the LIKE keyword, see SQL Server 2000 Books
Online.
Although Microsoft SQL Server traditionally has supported the SQL-92-standard
as well as some nonstandard NULL behaviors, it supports the use of NULL in Oracle.
SET ANSI_NULLS should be set to ON for executing distributed queries.
The SQL Server ODBC driver and OLE DB Provider for SQL Server automatically SET
ANSI_NULLS to ON when connecting. This setting can be configured in ODBC data sources, in ODBC
connection attributes, or in OLE DB connection properties that are set in the application
before connecting to SQL Server. SET ANSI_NULLS defaults to OFF for connections from
DB‑Library applications.
When SET ANSI_DEFAULTS is ON, SET ANSI_NULLS is enabled.
For more information about the use of NULL, see SQL Server 2000 Books
Online.
Oracle uses two pipe symbols (||) as the string concatenation operator, and SQL
Server uses the plus sign (+). This difference requires minor revision in your application
program code.
|
Oracle
|
Microsoft SQL Server
|
|
SELECT FNAME||' '||LNAME AS NAME
FROM STUDENT_ADMIN.STUDENT
|
SELECT FNAME +' '+ LNAME AS NAME
FROM STUDENT_ADMIN.STUDENT
|
The control-of-flow language controls the flow of execution of SQL statements,
statement blocks, and stored procedures. PL/SQL and Transact‑SQL provide many of the same
constructs, although there are some syntax differences.
These are the keywords supported by each RDBMS.
|
Statement
|
Oracle PL/SQL
|
Microsoft SQL Server Transact-SQL
|
|
Declare variables
|
DECLARE
|
DECLARE
|
|
Statement block
|
BEGIN...END;
|
BEGIN...END
|
|
Conditional processing
|
IF…THEN,
ELSIF…THEN,
ELSE
ENDIF;
|
IF…[BEGIN…END]
ELSE <condition>
[BEGIN…END]
ELSE IF <condition>
CASE expression
|
|
Unconditional exit
|
RETURN
|
RETURN
|
|
Unconditional exit to the statement following the end of the current
program block
|
EXIT
|
BREAK
|
|
Restarts a WHILE loop
|
N/A
|
CONTINUE
|
|
Wait for a specified interval
|
N/A (dbms_lock.sleep)
|
WAITFOR
|
|
Loop control
|
WHILE LOOP…END LOOP;
LABEL…GOTO LABEL;
FOR…END LOOP;
LOOP…END LOOP;
|
WHILE <condition>
BEGIN… END
LABEL…GOTO LABEL
|
|
Statement (continued)
|
Oracle PL/SQL (continued)
|
Microsoft SQL Server Transact-SQL (continued)
|
|
Program comments
|
/* … */, --
|
/* … */, --
|
|
Print output
|
RDBMS_OUTPUT.PUT_LINE
|
PRINT
|
|
Raise program error
|
RAISE_APPLICATION_ERROR
|
RAISERROR
|
|
Execute program
|
EXECUTE
|
EXECUTE
|
|
Statement terminator
|
Semicolon (;)
|
N/A
|
Transact‑SQL and PL/SQL variables are created with the DECLARE keyword.
Transact‑SQL variables are identified with @) and, like PL/SQL variables, are initialized
to a null value when they are first created.
|
Oracle
|
Microsoft SQL Server
|
|
DECLARE
VSSN CHAR(9);
VFNAME VARCHAR2(12);
VLNAME VARCHAR2(20);
VBIRTH_DATE DATE;
VLOAN_AMOUNT NUMBER(12,2);
|
DECLARE
@VSSN CHAR(9),
@VFNAME VARCHAR2(12),
@VLNAME VARCHAR2(20),
@VBIRTH_DATE DATETIME,
@VLOAN_AMOUNT NUMERIC(12,2)
|
Transact‑SQL does not support the %TYPE and %ROWTYPE variable data type
definitions. A Transact‑SQL variable cannot be initialized in the DECLARE command. The
Oracle NOT NULL and CONSTANT keywords cannot be used in Microsoft SQL Server data type
definitions.
Like Oracle LONG and LONG RAW data types, text and
image data types cannot be used for variable declarations.
Additionally, the PL/SQL style record and table definitions are not
supported.
Oracle and Microsoft SQL Server offer these ways to assign values to local
variables.
|
Oracle
|
Microsoft SQL Server
|
|
Assignment operator (:=)
|
SET @local_variable = value
|
|
SELECT...INTO syntax for selecting column values from a single row
|
SELECT @local_variable = expression
[FROM…] for assigning a literal value, an expression involving other local
variables, or a column value from a single row
|
|
FETCH…INTO syntax
|
FETCH…INTO syntax
|
Here are some syntax examples.
|
Oracle
|
Microsoft SQL Server
|
|
DECLARE VSSN CHAR(9);
VFNAME VARCHAR2(12);
VLNAME VARCHAR2(20);
BEGIN
VSSN := '123448887';
SELECT FNAME, LNAME INTO VFNAME, VLNAME FROM STUDENTS WHERE
SSN=VSSN;
END;
|
DECLARE @VSSN CHAR(9),
@VFNAME VARCHAR(12),
@VLNAME VARCHAR(20)
SET @VSSN = '12355887'
SELECT @VFNAME=FNAME, @VLNAME=LNAME FROM STUDENTS WHERE SSN =
@VSSN
|
Oracle PL/SQL and Microsoft SQL Server Transact‑SQL support the use of
BEGIN…END terminology to specify statement blocks. Transact‑SQL does not require
the use of a statement block following the DECLARE statement. The BEGIN…END statement
blocks are required in Microsoft SQL Server for IF statements and WHILE loops if more than one
statement is executed.
|
Oracle
|
Microsoft SQL Server
|
|
DECLARE
DECLARE VARIABLES ...
BEGIN -- THIS IS REQUIRED SYNTAX
PROGRAM_STATEMENTS ...
IF ...THEN
STATEMENT1;
STATEMENT2;
STATEMENTN;
END IF;
WHILE ... LOOP
STATEMENT1;
STATEMENT2;
STATEMENTN;
END LOOP;
END; -- THIS IS REQUIRED SYNTAX
|
DECLARE
DECLARE VARIABLES ...
BEGIN -- THIS IS OPTIONAL SYNTAX
PROGRAM_STATEMENTS ...
IF ...
BEGIN
STATEMENT1
STATEMENT2
STATEMENTN
END
WHILE ...
BEGIN
STATEMENT1
STATEMENT2
STATEMENTN
END
END -- THIS IS REQUIRED SYNTAX
|
The Microsoft SQL Server Transact‑SQL conditional statement includes IF
and ELSE rather than the ELSIF statement in Oracle PL/SQL. Multiple IF statements can be nested
to achieve the same effect. For extensive conditional tests, the CASE expression may be easier
to read.
|
Oracle
|
Microsoft SQL Server
|
|
DECLARE
VDEGREE_PROGRAM CHAR(1);
VDEGREE_PROGRAM_NAME VARCHAR2(20);
BEGIN
VDEGREE_PROGRAM := 'U';
IF VDEGREE_PROGRAM = 'U' THEN
VDEGREE_PROGRAM_NAME :=
'Undergraduate';
ELSIF VDEGREE_PROGRAM = 'M' THEN
VDEGREE_PROGRAM_NAME :=
'Masters';
ELSIF VDEGREE_PROGRAM = 'P' THEN
VDEGREE_PROGRAM_NAME := 'PhD';
ELSE VDEGREE_PROGRAM_NAME :=
'Unknown';
END IF;
END;
|
DECLARE
@VDEGREE_PROGRAM CHAR(1),
@VDEGREE_PROGRAM_NAME VARCHAR(20)
SELECT @VDEGREE_PROGRAM = 'U'
SELECT @VDEGREE_PROGRAM_NAME =
CASE @VDEGREE_PROGRAM
WHEN 'U' THEN 'Undergraduate'
WHEN 'M' THEN 'Masters'
WHEN 'P' THEN 'PhD'.
ELSE 'Unknown'
END
|
Oracle PL/SQL provides the unconditional LOOP and FOR LOOP. Transact‑SQL
offers the WHILE loop and the GOTO statement for looping purposes.
WHILE Boolean_expression
{sql_statement | statement_block}
[BREAK] [CONTINUE]
The WHILE loop tests a Boolean expression for the repeated execution of one or
more statements. The statement(s) are executed repeatedly as long as the specified expression
evaluates to TRUE. If multiple statements are to be executed, they must be placed within a
BEGIN…END block.
|
Oracle
|
Microsoft SQL Server
|
|
DECLARE
COUNTER NUMBER;
BEGIN
COUNTER := 0
WHILE (COUNTER <5) LOOP
COUNTER := COUNTER + 1;
END LOOP;
END;
|
DECLARE
@COUNTER NUMERIC
SELECT@COUNTER = 1
WHILE (@COUNTER <5)
BEGIN
SELECT @COUNTER = @COUNTER +1
END
|
Statement execution can be controlled from inside the loop with the BREAK and
CONTINUE keywords. The BREAK keyword causes an unconditional exit from the WHILE loop, and the
CONTINUE keyword causes the WHILE loop to restart, skipping any statements that follow. The
BREAK keyword is equivalent to the Oracle PL/SQL EXIT keyword. Oracle does not have an
equivalent to CONTINUE.
Both Oracle and Microsoft SQL Server have GOTO statements, with different
syntax. The GOTO statement causes the execution of a Transact‑SQL batch to jump to a
label. None of the statements between the GOTO statement and the label are executed.
|
Oracle
|
Microsoft SQL Server
|
|
GOTO label;
<<label name here>>
|
GOTO label
:label
|
The Transact‑SQL PRINT statement performs the same operation as the
PL/SQL RDBMS_OUTPUT.put_line procedure. It is used for printing
user-specified messages.
The message limit for the PRINT statement is 8,000 characters. Variables that
are defined using the char or varchar data
type can be embedded in the printed statement. If any other data type is used, the CONVERT or
CAST function must be used. Local variables, global variables, and text can be printed. Both
single and double quotation marks can be used to enclose text.
Both Microsoft SQL Server and Oracle have RETURN statements. RETURN lets your
program exit unconditionally from a query or procedure. RETURN is immediate and complete and
can be used at any point to exit from a procedure, batch, or statement block. Statements
following RETURN are not executed.
|
Oracle
|
Microsoft SQL Server
|
|
RETURN expression:
|
RETURN integer_expression
|
The Transact‑SQL RAISERROR statement returns a user-defined error message
and sets a system flag to record that an error has occurred. It is similar in function to the
PL/SQL raise_application_error exception handler.
The RAISERROR statement allows the client to retrieve an entry from the
sysmessages table or build a message dynamically with user-specified
severity and state information. When defined, this message is sent back to the client as a
server error message.
RAISERROR ({msg_id | msg_str}, severity, state
[, argument1 [, argument2]])
[WITH options]
When converting your PL/SQL programs, it may not be necessary to use the
RAISERROR statement. In the following code example, the PL/SQL program uses the raise_application_error exception handler, and the Transact‑SQL program
uses nothing. The raise_application_error exception handler has
been included to prevent the PL/SQL program from possibly returning an ambiguous unhandled exception error message. Instead, it always returns the Oracle error
message (SQLERRM) when an unanticipated problem occurs.
When a Transact‑SQL program fails, it always returns a detailed error
message to the client program. Therefore, unless some specialized error handling is required,
the RAISERROR statement is not always needed.
|
Oracle
|
Microsoft SQL Server
|
|
CREATE OR REPLACE FUNCTION
DEPT_ADMIN.DELETE_DEPT
(VDEPT IN VARCHAR2) RETURN NUMBER AS
BEGIN
DELETE FROM DEPT_ADMIN.DEPT
WHERE DEPT = VDEPT;
RETURN(SQL%ROWCOUNT);
EXCEPTION
WHEN OTHER THEN
RAISE_APPLICATION_ERROR (-20001,SQLERRM);
END DELETE_DEPT;
/
|
CREATE PROCEDURE
DEPT_ADMIN.DELETE_DEPT
@VDEPT VARCHAR(4) AS
DELETE FROM DEPT_DB.DBO.DEPT
WHERE DEPT = @VDEPT
RETURN @@ROWCOUNT
GO
|
Oracle always requires that cursors be used with SELECT statements, regardless
of the number of rows requested from the database. In Microsoft SQL Server, a SELECT statement
that is not enclosed within a cursor returns rows to the client as a default result set. This
is an efficient way to return data to a client application.
SQL Server provides two interfaces for cursor functions. When cursors are used
in Transact‑SQL batches or stored procedures, SQL statements can be used to declare,
open, and fetch from cursors as well as positioned updates and deletes. When cursors from a
DB‑Library, ODBC, or OLE DB program are used, the SQL Server client libraries
transparently call built-in server functions to handle cursors more efficiently.
When porting a PL/SQL procedure from Oracle, first determine whether cursors
are needed to do the same function in Transact‑SQL. If the cursor returns only a set of
rows to the client application, use a noncursor SELECT statement in Transact‑SQL to
return a default result set. If the cursor is used to load data a row at a time into local
procedure variables, you must use cursors in Transact‑SQL.
The table shows the syntax for using cursors.
|
Operation
|
Oracle
|
Microsoft SQL Server
|
|
Declaring a cursor
|
CURSOR cursor_name [(cursor_parameter(s))]
IS select_statement;
|
DECLARE cursor_name CURSOR
[LOCAL | GLOBAL]
[FORWARD_ONLY | SCROLL]
[STATIC | KEYSET | DYNAMIC | FAST_FORWARD]
[READ_ONLY | SCROLL_LOCKS | OPTIMISTIC]
[TYPE_WARNING]
FOR select_statement
[FOR UPDATE [OF column_name
[,…n]]]
|
|
Opening a cursor
|
OPEN cursor_name [(cursor_parameter(s))];
|
OPEN cursor_name
|
|
Fetching from cursor
|
FETCH cursor_name INTO variable(s)
|
FETCH [[NEXT | PRIOR | FIRST | LAST | ABSOLUTE
{n | @nvar} | RELATIVE
{n | @nvar}]
FROM] cursor_name
[INTO @variable(s)]
|
|
Update fetched row
|
UPDATE table_name
SET statement(s)…
WHERE CURRENT OF cursor_name;
|
UPDATE table_name
SET statement(s)…
WHERE CURRENT OF cursor_name
|
|
Delete fetched row
|
DELETE FROM table_name
WHERE CURRENT OF cursor_name;
|
DELETE FROM table_name
WHERE CURRENT OF cursor_name
|
|
Closing cursor
|
CLOSE cursor_name;
|
CLOSE cursor_name
|
|
Remove cursor data structures
|
N/A
|
DEALLOCATE cursor_name
|
Although the Transact‑SQL DECLARE CURSOR statement does not support the
use of cursor arguments, it does support local variables. The values of these local variables
are used in the cursor when it is opened. Microsoft SQL Server offers many additional
capabilities in its DECLARE CURSOR statement.
The INSENSITIVE option is used to define a cursor that makes a temporary copy
of the data to be used by that cursor. All of the requests to the cursor are answered by this
temporary table. Consequently, modifications made to base tables are not reflected in the data
returned by fetches made to this cursor. Data accessed by this type of cursor cannot be
modified.
Applications can request a cursor type and then execute a Transact‑SQL
statement that is not supported by server cursors of the type requested. SQL Server returns an
error that indicates the cursor type has changed, or given a set of factors, implicitly
converts a cursor. For a complete list of factors that trigger SQL Server 2000 to implicitly
convert a cursor from one type to another, see SQL Server 2000 Books Online.
The SCROLL option allows backward, absolute, and relative fetches in addition
to forward fetches. A scroll cursor uses a keyset cursor model in which committed deletes and
updates made to the underlying tables by any user are reflected in subsequent fetches. This is
true only if the cursor is not declared with the INSENSITIVE option.
If the READ ONLY option is chosen, updates are prevented from occurring against
any row within the cursor. This option overrides the default capability of a cursor to be
updated.
The UPDATE [OF column_list] statement is used to
define updatable columns within the cursor. If [OF column_list] is
supplied, only the columns listed allow modifications. If no list is supplied, all of the
columns can be updated unless the cursor has been defined as READ ONLY.
It is important to note that the name scope for a SQL Server cursor is the
connection itself. This is different from the name scope of a local variable. A second cursor
with the same name as an existing cursor on the same user connection cannot be declared until
the first cursor is deallocated.
Transact‑SQL does not support the passing of arguments to a cursor when
it is opened, unlike PL/SQL. When a Transact‑SQL cursor is opened, the result set
membership and ordering are fixed. Updates and deletes that have been committed against the
base tables of the cursor by other users are reflected in fetches made against all cursors
defined without the INSENSITIVE option. In the case of an INSENSITIVE cursor, a temporary table
is generated.
Oracle cursors can move in a forward direction only-there is no backward or
relative scrolling capability. SQL Server cursors can scroll forward and backward with the
fetch options shown in the following table. These fetch options can be used only when the
cursor is declared with the SCROLL option.
|
Scroll option
|
Description
|
|
NEXT
|
Returns the first row of the result set if this is the first fetch
against the cursor; otherwise, it moves the cursor one row within the result set. NEXT is
the primary method used to move through a result set. NEXT is the default cursor
fetch.
|
|
PRIOR
|
Returns the previous row within the result set.
|
|
FIRST
|
Moves the cursor to the first row within the result set and returns the
first row.
|
|
LAST
|
Moves the cursor to the last row within the result set and returns the
last row.
|
|
ABSOLUTE n
|
Returns the nth row within the result set. If
n is a negative value, the returned row is the nth row
counting backward from the last row of the result set.
|
|
RELATIVE n
|
Returns the nth row after the currently
fetched row. If n is a negative value, the returned row is
the nth row counting backward from the relative position of
the cursor.
|
The Transact‑SQL FETCH statement does not require the INTO clause. If
return variables are not specified, the row is automatically returned to the client as a
single-row result set. However, if your procedure must get the rows to the client, a noncursor
SELECT statement is much more efficient.
The @@FETCH_STATUS function is updated following each FETCH. It is similar in
use to the CURSOR_NAME%FOUND and CURSOR_NAME%NOTFOUND variables used in PL/SQL. The
@@FETCH_STATUS function is set to the value of 0 following a successful fetch. If the fetch
tries to read beyond the end of the cursor, a value of -1 is returned. If the requested row has
been deleted from the table after the cursor was opened, the @@FETCH_STATUS function returns
-2. The value of -2 usually occurs only in a cursor declared with the SCROLL option. This
variable must be checked following each fetch to ensure the validity of the data.
SQL Server does not support Oracle's cursor FOR loop syntax.
The CURRENT OF clause syntax and function for updates and deletes is the same
in both PL/SQL and Transact‑SQL. A positioned UPDATE or DELETE is performed against the
current row within the specified cursor.
The Transact‑SQL CLOSE CURSOR statement closes the cursor but leaves the
data structures accessible for reopening. The PL/SQL CLOSE CURSOR statement closes and releases
all data structures.
Transact‑SQL requires the use of the DEALLOCATE CURSOR statement to
remove the cursor data structures. The DEALLOCATE CURSOR statement is different from CLOSE
CURSOR in that a closed cursor can be reopened. The DEALLOCATE CURSOR statement releases all
data structures associated with the cursor and removes the definition of the cursor.
The example below shows equivalent cursor statements in PL/SQL and
Transact‑SQL.
|
Oracle
|
Microsoft SQL Server
|
|
DECLARE
VSSN CHAR(9);
VFNAME VARCHAR(12);
VLNAME VARCHAR(20);
CURSOR CUR1 IS
SELECT SSN, FNAME, LNAME
FROM STUDENT ORDER BY LNAME;
BEGIN
OPEN CUR1;
FETCH CUR1 INTO VSSN, VFNAME, VLNAME;
WHILE (CUR1%FOUND) LOOP
FETCH CUR1 INTO VSSN, VFNAME, VLNAME;
END LOOP;
CLOSE CUR1;
END;
|
DECLARE
@VSSN CHAR(9),
@VFNAME VARCHAR(12),
@VLNAME VARCHAR(20)
DECLARE curl CURSOR FOR
SELECT SSN, FNAME, LNAME
FROM STUDENT ORDER BY SSN
OPEN CUR1
FETCH NEXT FROM CUR1
INTO @VSSN, @VFNAME, @VLNAME
WHILE (@@FETCH_STATUS <> -1)
BEGIN
FETCH NEXT FROM CUR1
INTO @VSSN, @VFNAME, @VLNAME
END
CLOSE CUR1
DEALLOCATE CUR1
|
For more information about cursors, see "Cursors" in SQL Server 2000 Books
Online.
This section provides
information about several SQL Server tools you can use to tune Transact-SQL statements.
Microsoft SQL Server 2000 is a largely auto-configuring and self-tuning
database server, dramatically reducing the burden of server configuration on the database
administrator. In most cases, SQL Server runs best when these autotuning parameters are left at
their default settings and when administrators allow SQL Server to handle the performance
tuning. For the latest information about tuning your SQL Server database, see http://msdn.microsoft.com/sqlserver.
You can use the graphical showplan feature of SQL Query Analyzer to learn more
about how the optimizer will process your statement.
This graphical tool
captures a continuous record of server activity in real-time. SQL Profiler monitors many
different server events and event categories, filters these events with user-specified
criteria, and outputs a trace to the screen, a file, or another server running SQL
Server.
SQL Profiler can be used to:
·
Monitor the performance of SQL Server.
·
Debug Transact-SQL statements and stored procedures.
·
Identify slow-executing queries.
·
Troubleshoot problems in SQL Server by capturing all the events that lead up to a particular
problem, and then replaying the events on a test system to replicate and isolate the
problem.
·
Test SQL statements and stored procedures in the development phase of a project by
single-stepping through statements, one line at a time, to confirm that the code works as
expected.
·
Capture events on a production system and replay those captured events on a test system,
thereby re-creating what happened in the production environment for testing or debugging
purposes. Replaying captured events on a separate system allows the users to continue using the
production system without interference.
SQL Profiler provides a graphical user interface to a set of extended stored
procedures. You can also use these extended stored procedures directly. Therefore, it is
possible to create your own application that uses the SQL Profiler extended stored procedures
to monitor SQL Server.
The SET statement can set SQL Server query-processing options for the duration
of your work session, or for the duration of a running trigger or a stored procedure.
The SET FORCEPLAN ON statement forces the optimizer to process joins in the
same order as the tables appear in the FROM clause, similar to the ORDERED hint used with the
Oracle optimizer.
The SET SHOWPLAN_ALL and SET SHOWPLAN_TEXT statements return only query or
statement execution plan information and do not execute the query or statement. To execute the
query or statement, set the appropriate showplan statement OFF. The query or statement will
then execute. The SHOWPLAN option provides results similar to the Oracle EXPLAIN PLAN tool.
With SET STATISTICS PROFILE ON, each executed query returns its regular result
set, followed by an additional result set that shows a profile of the query execution. Other
options include SET STATISTICS IO and SET STATISTICS TIME.
Transact‑SQL statement processing consists of two phases, compilation and
execution. The NOEXEC option compiles each query but does not execute it. After NOEXEC is set
ON, no subsequent statements are executed (including other SET statements) until NOEXEC is set
OFF.
SET SHOWPLAN ON
SET NOEXEC ON
Go
SELECT * FROM DEPT_ADMIN.DEPT,
STUDENT_ADMIN.STUDENT
WHERE MAJOR = DEPT
Go
STEP 1
The type of query is SETON
STEP 1
The type of query is SETON
STEP 1
The type of query is SELECT
FROM TABLE
DEPT_ADMIN.DEPT
Nested iteration
Table Scan
FROM TABLE
STUDENT_ADMIN.STUDENT
Nested iteration
Table Scan
Oracle requires the use of hints to influence the operation and performance of
its cost-based optimizer. The SQL Server cost-based optimizer does not require the use of hints
to assist in its query evaluation process. They are offered; however, as some situations do
warrant their use.
The INDEX = {index_name | index_id} hint specifies the index name or ID to use for that table. An
index_id of 0 forces a table scan, while an index_id of 1 forces the use of a clustered index, if it exists. This is
similar to the index hints used in Oracle.
The SQL Server FASTFIRSTROW hint directs the optimizer to use a nonclustered
index if its column order matches the ORDER BY clause. This hint operates in a similar fashion
to the Oracle FIRST_ROWS hint.
Microsoft SQL Server 2000 introduces new features to support XML functionality.
Using XML, you can:
·
SELECT, INSERT and UPDATE a SQL Server database.
·
Use Xpath queries against XDR (XML Data Reduced schemas).
·
Format the results of Transact‑SQL statements in XML using FOR XML.
For more information about SQL Server XML support, see Chapter 31, "Exposing
SQL Server Data to the Web with XML" in the Microsoft SQL Server 2000
Resource Kit and "XML and Internet Support Overview" in SQL Server 2000 Books Online.
You can also search the MSDN® Library for the articles
"Duwamish Online SQL Server XML Catalog Browsing" and "SQL Server XML and Web Application
Architecture" at http://msdn.microsoft.com/xml.
This section provides
information about the ways Oracle and SQL Server use ODBC and information about developing or
migrating applications with ODBC.
Use the following process when you convert your application code from Oracle to
SQL Server:
1. Consider converting your
application to ODBC if it is written using Oracle Pro*C or the Oracle Call Interface (OCI).
2. Understand SQL Server
default result sets and cursor options, and choose the fetching strategy that is most efficient
for your application.
3. Remap Oracle ODBC SQL data
types to SQL Server ODBC SQL data types where appropriate.
4. Use the ODBC Extended SQL
extensions to create generic SQL statements.
5. Determine if manual commit
mode is required for the SQL Server-based application.
6. Test the performance of
your application(s) and modify the program(s) as necessary.
Microsoft provides both 16-bit and 32-bit versions of its ODBC SQL Server
driver. The 32-bit ODBC SQL Server driver is thread-safe. The driver serializes shared access
by multiple threads to shared statement handles (hstmt), connection handles (hdbc), and
environment handles (henv). However, the ODBC program is still responsible for keeping
operations within statements and connection spaces in the proper sequence, even when the
program uses multiple threads.
Because the ODBC driver for Oracle can be supplied by one of many possible
vendors, there are many possible scenarios regarding architecture and operation. You must
contact the vendor to ensure that the ODBC driver meets your application's requirements.
In most cases, the ODBC driver for Oracle uses SQL*Net to connect to the Oracle
RDBMS. SQL*Net may not be used, however, when connecting to Personal Oracle.
The illustration shows the application/driver architecture for 32-bit
environments.
The term thunking means intercepting a function call, doing a special
processing to translate between 16-bit and 32-bit code, and then transferring control to a
target function. The ODBC Cursor Library optionally resides between the driver manager and its
driver. This library provides scrollable cursor services on top of drivers that support only
forward-only cursors.
Oracle and SQL Server treat result sets and cursors differently. Understanding
these differences is essential for successfully moving a client application from Oracle to SQL
Server and having it perform optimally.
In Oracle, any result set from a SELECT command is treated as a forward-only
cursor when fetched in the client application. This is true whether you are using ODBC, OCI, or
Embedded SQL as your development tool.
By default, each Oracle FETCH command issued by the client program (for
example, SQLFetch in ODBC) causes a round-trip across the network to
the server to return one row. If a client application wants to fetch more than one row at a
time across the network, it must set up an array in its program and perform an array fetch.
Between fetches, no locks are held at the server for a read-only cursor because
of Oracle's multiversioning concurrency model. When the program specifies an updatable cursor
with the FOR UPDATE clause, all of the requested rows in the SELECT command are locked when the
statement is opened. These row-level locks remain in place until the program issues a COMMIT or
ROLLBACK request.
In SQL Server, a SELECT statement is not always associated with a cursor at the
server. By default, SQL Server simply streams all the result set rows from a SELECT statement
back to the client. This streaming starts as soon as the SELECT is executed. Result set streams
can also be returned by SELECT statements within stored procedures. Additionally, a single
stored procedure or batch of commands can stream back multiple result sets in response to a
single EXECUTE statement.
The SQL Server client is responsible for fetching these default result sets as
soon as they are available. For default result sets, fetches at the client do not result in
round-trips to the server. Instead, fetches from a default result set pull data from local
network buffers into program variables. This default result set model creates an efficient
mechanism to return multiple rows of data to the client in a single round-trip across this
network. Minimizing network round-trips is usually the most important factor in client/server
application performance.
Compared to Oracle's cursors, default result sets put some additional
responsibilities on the SQL Server client application. The SQL Server client application must
immediately fetch all the result set rows returned by an EXECUTE statement. If the application
needs to present rows incrementally to other parts of the program, it must buffer the rows to
an internal array. If it fails to fetch all result set rows, the connection to SQL Server
remains busy.
If this occurs, no other work (such as UPDATE statements) can be executed on
that connection until the entire result set rows are fetched or the client cancels the request.
Moreover, the server continues to hold share locks on table data pages until the fetch has
completed. The fact that these share locks are held until a fetch is complete make it mandatory
that you fetch all rows as quickly as possible. This technique is in direct contrast to the
incremental style of fetch that is commonly found in Oracle applications.
Microsoft SQL Server offers server cursors to
address the need for incremental fetching of result sets across the network. Server cursors can
be requested in an application by simply calling SQLSetStmtOption to
set the SQL_CURSOR_TYPE option.
When a SELECT statement is executed as a server cursor, only a cursor
identifier is returned by the EXECUTE statement. Subsequent fetch requests pass the cursor
identifier back to the server along with a parameter specifying the number of rows to fetch at
once. The server returns the number of rows requested.
Between fetch requests, the connection remains free to issue other commands,
including other cursor OPEN or FETCH requests. In ODBC terms, this means that server cursors
allow the SQL Server driver to support multiple active statements on a single connection.
Furthermore, server cursors do not usually hold locks between fetch requests,
so you are free to pause between fetches for user input without affecting other users. Server
cursors can be updated in place using either optimistic conflict detection or pessimistic
scroll locking concurrency options.
Although these features make programming with server cursors more familiar to
Oracle developers than using default result sets, they are not free. Compared to default result
sets:
·
Server cursors are more expensive in terms of server resources, because temporary storage space
is used to maintain cursor state information at the server.
·
Server cursors are more expensive to retrieve a given result set of data with, because the
EXECUTE statement and each fetch request in a server cursor requires a separate round-trip to
the server.
·
Server cursors are less flexible in terms of the kind of batches and stored procedures they
support. This is because a server cursor can execute only one SELECT statement at a time,
whereas default result sets can be used for batches and stored procedures that return multiple
result sets or include statements other than SELECT statements.
For these reasons, it is recommended that you limit the use of server cursors
to those parts of your application that need their features.
The Oracle RDBMS supports only forward-scrolling cursors. Each row is fetched
to the application in the order that it was specified in the query. Oracle does not accept
requests to move backward to a previously fetched row. The only way to move backward is to
close the cursor and reopen it. Unfortunately, you are repositioned back to the first row in
the active query set.
Because SQL Server supports scrollable cursors, you can position a SQL Server
cursor at any row location. You can scroll both forward and backward. For many applications
involving a user interface, scrollability is a useful feature. With scrollable cursors, your
application can fetch a screen full of rows at a time, and only fetch additional rows as the
user asks for them.
Although Oracle does not directly support scrollable cursors, this limitation
can be minimized by using one of several ODBC options. For example, some Oracle ODBC drivers,
such as the one that ships with the Microsoft Developer Studio® visual development system, offer client-based scrollable cursors
in the driver itself.
Alternatively, the ODBC Cursor Library supports block scrollable cursors for
any ODBC driver that complies with the Level One conformance level. Both of these client cursor
options support scrolling by using the RDBMS for forward-only fetching, and by caching result
set data in memory or on disk. When data is requested, the driver retrieves it from the RDBMS
or its local cache as needed.
Client-based cursors also support positioned UPDATE and DELETE statements for
the result sets generated by SELECT statements. The cursor library constructs an UPDATE or
DELETE statement with a WHERE clause that specifies the cached value for each column in a
row.
If you need scrollable cursors and are trying to maintain the same source code
for both Oracle and SQL Server implementations, the ODBC Cursor Library is a useful option. For
more information about the ODBC Cursor Library, see the ODBC documentation.
With all of the options that SQL Server offers for fetching data, it is
sometimes difficult to decide what to use and when. Here are some useful guidelines:
·
Default result sets are always the fastest way to get an entire set of data from SQL Server to
the client. Look for opportunities in your application where you can use this to your
advantage. Batch report generation, for example, generally processes an entire result set to
completion, with no user interaction and no updates in the middle of processing.
·
If your program requires updatable cursors, use server cursors. Default result sets are never
updatable when using positioned UPDATE or DELETE statements. Additionally, server cursors are
better at updating than client-based cursors, which have to simulate a positioned UPDATE or
DELETE by constructing an equivalent searched UPDATE or DELETE statement.
·
If your program needs scrollable, read-only cursors, both the ODBC Cursor Library and server
cursors are good choices. The ODBC Cursor Library gives you compatible behavior across SQL
Server and Oracle, and server cursors give you more flexibility as to how much data to fetch
across the network at one time.
·
When you use default result sets or ODBC Cursor Library cursors built on top of default result
sets, be sure to fetch to the end of a result set as quickly as possible to avoid holding share
locks at the server.
·
When you use server cursors, be sure to use SQLExtendedFetch to fetch
in blocks of rows rather than a single row at a time. This is the same as array-type fetching
in Oracle applications. Every fetch request on a server cursor requires a round-trip from the
application to the RDBMS on the network.
·
Shopping provides an analogy. Assume you purchase several bags of goods, load one bag into your
car, drive home, drop it off, and return for the next bag. This is an unlikely scenario, but
this is what you do to SQL Server and your program by making single-row fetches from a server
cursor.
·
If your program requires only forward-only, read-only cursors but depends on multiple open
cursors on the same connection, use default result sets when you know you can fetch the entire
result set immediately into program variables. Use server cursors when you do not know if you
can fetch all of the rows immediately.
This strategy is not as difficult as it sounds. Most programmers know when they
are issuing a singleton select that can return a maximum of one row. For singleton fetches,
using a default result set is more efficient than using a server cursor.
For more information about cursor implementations, see SQL Server 2000 Books
Online.
The ODBC driver uses a statement handle (hstmt) to track each active SQL
statement within the program. The statement handle is always associated with a RDBMS connection
handle (hdbc). The ODBC driver manager uses the connection handle to send the requested SQL
statement to the specified RDBMS. Most ODBC drivers for Oracle allow multiple statement handles
per connection. However, the SQL Server ODBC driver allows only one active statement handle per
connection when using default result sets. The SQLGetInfo function of
this SQL Server driver returns the value 1 when queried with the SQL_ACTIVE_STATEMENTS option.
When statement options are set in a way that uses server cursors, multiple active statements
per connection handle are supported.
For more information about setting statement options to request server cursors,
see SQL Server 2000 Books Online.
The SQL Server ODBC driver offers a richer set of data type mappings than most
available Oracle ODBC drivers.
|
Microsoft SQL Server data type
|
ODBC SQL data type
|
|
binary
|
SQL_BINARY
|
|
bit
|
SQL_BIT
|
|
char, character
|
SQL_CHAR
|
|
datetime
|
SQL_TIMESTAMP
|
|
decimal, dec
|
SQL_DECIMAL
|
|
float, double precision, float(n) for n =
8-15
|
SQL_FLOAT
|
|
image
|
SQL_LONGVARBINARY
|
|
int, integer
|
SQL_INTEGER
|
|
money
|
SQL_DECIMAL
|
|
nchar
|
SQL_WCHAR
|
|
ntext
|
SQL_WLONGVARCHAR
|
|
numeric
|
SQL_NUMERIC
|
|
nvarchar
|
SQL_WVARCHAR
|
|
real, float(n) for n = 1-7
|
SQL_REAL
|
|
smalldatetime
|
SQL_TIMESTAMP
|
|
smallint
|
SQL_SMALLINT
|
|
smallmoney
|
SQL_DECIMAL
|
|
sysname
|
SQL_VARCHAR
|
|
text
|
SQL_LONGVARCHAR
|
|
timestamp
|
SQL_BINARY
|
|
tinyint
|
SQL_TINYINT
|
|
uniqueidentifier
|
SQL_GUID
|
|
varbinary
|
SQL_VARBINARY
|
|
varchar
|
SQL_VARCHAR
|
The timestamp data type is converted to the
SQL_BINARY data type. This is because the values in timestamp columns
are not datetime data, but rather binary(8)
data. They are used to indicate the sequence of SQL Server activity on the row.
The Oracle data type mappings for the SQL Server ODBC driver for Oracle are
shown in this table.
|
Oracle data type
|
ODBC SQL data type
|
|
CHAR
|
SQL_CHAR
|
|
DATE
|
SQL_TIMESTAMP
|
|
LONG
|
SQL_LONGVARCHAR
|
|
LONG RAW
|
SQL_LONGVARBINARY
|
|
NUMBER
|
SQL_FLOAT
|
|
NUMBER(P)
|
SQL_DECIMAL
|
|
NUMBER(P,S)
|
SQL_DECIMAL
|
|
RAW
|
SQL_BINARY
|
|
VARCHAR2
|
SQL_VARCHAR
|
Oracle ODBC drivers from other vendors can have alternative data type
mappings.
The ODBC Extended SQL standard provides SQL extensions to ODBC that support the
advanced nonstandard SQL feature set offered in both Oracle and SQL Server. This standard
allows the ODBC driver to convert generic SQL statements to Oracle- and SQL Server-native SQL
syntax.
This standard addresses outer joins, such as predicate escape characters,
scalar functions, date/time/timestamp values, and stored programs. This syntax is used to
identify these extensions:
--(*vendor(Microsoft), product(ODBC)
extension *)--
OR
{extension}
The conversion takes place at run time and does not require the revision of any
program code. In most application development scenarios, the best approach is to write one
program and allow ODBC to perform the RDBMS conversion process when the program is
run.
Oracle and SQL Server do not have compatible outer join syntax. This can be
resolved by using the ODBC extended SQL outer join syntax. The Microsoft SQL Server syntax is
the same as the ODBC Extended SQL/SQL-92 syntax. The only difference is the
{oj } container.
|
ODBC Extended SQL and SQL-92
|
Oracle
|
Microsoft SQL Server
|
|
SELECT STUDENT.SSN, FNAME, LNAME, CCODE, GRADE
FROM {oj STUDENT LEFT OUTER JOIN GRADE ON STUDENT.SSN = GRADE.SSN}
|
SELECT STUDENT.SSN, FNAME, LNAME,
CCODE, GRADE
FROM STUDENT, GRADE
WHERE STUDENT.SSN = GRADE.SSN(+)
|
SELECT STUDENT.SSN, FNAME, LNAME,
CCODE, GRADE
FROM STUDENT LEFT OUTER JOIN GRADE
ON STUDENT.SSN = GRADE.SSN
|
ODBC provides three escape clauses for date, time, and timestamp values.
|
Category
|
Shorthand syntax
|
Format
|
|
Date
|
{d 'value'}
|
"yyyy-mm-dd"
|
|
Time
|
{t 'value'}
|
"hh:mm:ss"
|
|
Timestamp
|
{Ts 'value'}
|
"yyyy-mm-dd hh:mm:ss[.f…]"
|
The format of dates has more of an impact on Oracle applications than on SQL
Server-based applications. Oracle expects the date format to be "DD-MON-YY". In any other case,
the TO_CHAR or TO_DATE functions are used with a date format model to perform a format
conversion.
Microsoft SQL Server automatically converts most common date formats, and also
provides the CONVERT function when an automatic conversion cannot be performed.
As shown in the table, ODBC Extended SQL works with both databases. SQL Server
does not require a conversion function. Nevertheless, the ODBC shorthand syntax can be
generically applied to both Oracle and SQL Server.
|
ODBC Extended SQL
|
Oracle
|
Microsoft SQL Server
|
|
SELECT SSN, FNAME, LNAME, BIRTH_DATE
FROM STUDENT WHERE BIRTH_DATE < {D '1970-07-04'}
|
SELECT SSN, FNAME, LNAME,
BIRTH_DATE
FROM STUDENT
WHERE BIRTH_DATE <
TO_DATE('1970-07-04', 'YYYY-MM-DD')
|
SELECT SSN, FNAME, LNAME,
BIRTH_DATE
FROM STUDENT
WHERE BIRTH_DATE < '1970-07-04'
|
The ODBC shorthand syntax for calling stored programs supports Microsoft SQL
Server stored procedures, and Oracle stored procedures, functions, and packages. The optional
"?=" captures the return value for an Oracle function or a SQL Server procedure. The parameter
syntax is used to pass and return values to and from the called program. In most situations,
the same syntax can be generically applied to Oracle- and SQL Server-based applications.
In the following example, the SHOW_RELUCTANT_STUDENTS function is part of the
Oracle package P1. This function must exist in a package because it returns multiple rows from
a PL/SQL cursor. When you call a function or procedure that exists in a package, the package
name must be placed in front of the program name.
The SHOW_RELUCTANT_STUDENTS function in the package P1 uses a package cursor to
retrieve multiple rows of data. Each row must be requested with a call to this function. If
there are no more rows to retrieve, the function returns the value of 0, indicating that there
are no more rows to retrieve. The resulting performance of this sample Oracle package and its
function might be less than satisfactory. In this example, the SQL Server procedure is more
efficient.
|
Generic ODBC Extended SQL
|
Oracle
|
Microsoft SQL Server
|
|
{?=} call procedure_name[(parameter(s))]}
SQLExecDirect(hstmt1,(SQLCHAR *)"{? = call owner.procedure(?)}",
SQL_NTS);
|
SQLExecDirect(hstmt1, (SQLCHAR*)"{? = call
STUDENT_ADMIN.P1.
SHOW_RELUCTANT
_STUDENTS(?)}",
SQL_NTS);
|
SQLExecDirect(hstmt1, (SQLCHAR*)"{? = call
STUDENT_ADMIN.
SHOW_RELUCTANT
_STUDENTS}",
SQL_NTS);
|
Because of the variety of ODBC drivers for both Oracle and SQL Server, you may
not always get the same conversion string for the extended SQL functions. To assist with
application debugging issues, you might want to consider using the SQLNativeSql function. This function returns the SQL string as translated by the
driver.
The following are possible results for the following input SQL string that
contains the scalar function CONVERT. The column SSN is defined as
the type CHAR(9), and is converted to a numeric value.
|
Original statement
|
Converted Oracle statement
|
Converted SQL Server statement
|
|
SELECT (fn CONVERT
(SSN, SQL_INTEGER))
FROM STUDENT
|
SELECT TO_NUMBER(SSN)
FROM STUDENT
|
SELECT CONVERT(INT,SSN)
FROM STUDENT
|
Oracle automatically enters the transaction mode whenever a user modifies data.
This must be followed by an explicit COMMIT to write the changes to the database. If a user
wants to undo the changes, the user can issue the ROLLBACK statement.
By default, SQL Server automatically commits each change as it occurs. This is
called autocommit mode in ODBC. If you do not want this to occur, you can use the BEGIN
TRANSACTION statement to signal the start of a block of statements comprising a transaction.
After this statement is issued, it is followed by an explicit COMMIT TRANSACTION or ROLLBACK
TRANSACTION statement.
To ensure compatibility with your Oracle application, it is recommended that
you use the SQLConnectOption function to place your SQL Server-based
application in implicit transaction mode. The SQL_AUTOCOMMIT option must be set to
SQL_AUTOCOMMIT_OFF in order to accomplish this. This code excerpt demonstrates this
concept:
SQLSetConnectOption(hdbc1, SQL_AUTOCOMMIT,-sql_AUTOCOMMIT_OFF);
The SQL_AUTOCOMMIT_OFF option instructs the driver to use implicit
transactions. The default option SQL_AUTOCOMMIT_ON instructs the driver to use autocommit mode,
in which each statement is committed immediately after it is executed. Changing from manual
commit mode to autocommit mode commits any open transactions on the connection.
If the SQL_AUTOCOMMIT_OFF option is set, the application must commit or roll
back transactions explicitly with the SQLTransact function. This
function requests a commit or rollback operation for all active operations on all statement
handles associated with a connection handle. It can also request that a commit or rollback
operation be performed for all connections associated with the environment handle.
SQLTransact(henv1, hdbc1, SQL_ROLLBACK);
(SQLTransact(henv1, hdbc1, SQL_COMMIT);
When autocommit mode is off, the driver issues SET IMPLICIT_TRANSACTIONS ON
statement to the server. Starting with SQL Server 6.5, DDL statements are supported in this
mode.
To commit or roll back a transaction in manual commit mode, the application
must call SQLTransact. The SQL Server driver sends a COMMIT
TRANSACTION statement to commit a transaction, and a ROLLBACK TRANSACTION statement to roll
back a transaction.
Be aware that manual commit mode can adversely affect the performance of your
SQL Server-based application. Every commit request requires a separate round-trip to the server
to send the COMMIT TRANSACTION string.
If you have single atomic transactions (a single INSERT, UPDATE, or DELETE
immediately followed by a COMMIT), use the autocommit mode.
This section explains the differences between Oracle and Microsoft SQL Server
replication support.
|
Oracle
|
Microsoft SQL Server
|
|
Read-Only Snapshot Replication
|
Snapshot with immediate updating subscribers.
|
|
Multimaster Replication, Updatable snapshot
|
Transactional replication with immediate updating
subscribers—better for well-connected subscribers who are online when updating.
Merge Replication—better for mobile disconnected. This supports default and custom
conflict resolution.
|
As its name implies, SQL Server snapshot replication takes a picture, or
snapshot, of the published data in the database at a moment in time. Snapshot replication
requires less constant processor overhead than transactional replication because it does not
require continuous monitoring of data changes on source servers. Instead of copying INSERT,
UPDATE, and DELETE statements (characteristic of transactional replication), or data
modifications (characteristic of merge replication), Subscribers are updated by a total refresh
of the data set. Hence, snapshot replication sends all the data to the Subscriber instead of
sending only the changes.
SQL Server also offers transactional replication, a type of replication that
marks selected transactions in the Publisher's database transaction log for replication and
then distributes them asynchronously to Subscribers as incremental changes, while maintaining
transactional consistency.
SQL Server merge replication allows sites to make autonomous changes to
replicated data, and at a later time, merge changes made at all sites. Like Oracle, merge
replication supports both column-level and row-level conflict detection. That is, you can
define a conflict to be any change to the same row at two locations, or only when changes to
the same column(s) at two locations.
SQL Server offers heterogeneous replication, which is the simplest way to
publish data to a heterogeneous Subscriber by using ODBC or OLE/DB and creating a push
subscription from the Publisher to the ODBC Subscriber. As an alternative, however, you can
create a publication and then create an application with an embedded distribution control. The
embedded control implements the pull subscription from the Subscriber to the Publisher. For
ODBC Subscribers, the subscribing database has no administrative capabilities regarding the
replication being performed.
The table compares conflict-resolution mechanisms for Oracle and SQL
Server:
|
Oracle
|
Microsoft SQL Server
|
|
Site priority or priority value resolvers programmed using PL/SQL
|
Priority-based resolution using COM or Transact-SQL.
|
|
Conflict resolution for column groups
|
Supported through custom resolvers.
|
|
Column-level and row-level conflict resolution
|
Support for both.
|
With Microsoft SQL Server, a distribution server connects to all subscription
servers as an ODBC or OLE/DB client. Replication requires that the ODBC 32-bit driver be
installed on all distribution servers. The SQL Server Setup program automatically installs the
necessary driver on Windows 2000-based computers.
You do not have to preconfigure ODBC Data Sources for SQL Server subscription
servers because the distribution process simply uses the subscriber's network name to establish
the connection.
SQL Server also includes an ODBC driver that supports Oracle subscriptions to
SQL Server. The driver exists only for Intel-based computers. To replicate to Oracle ODBC
subscribers, you must also obtain the appropriate Oracle SQL*Net driver from Oracle or from
your software vendor.
If a password is provided in the Windows registry, the Oracle ODBC driver
connects to Oracle without requesting a password. If a password is not provided in the Windows
registry, you must enter a username and a password for the Oracle ODBC data source when
specifying the DSN in the New ODBC Subscriber dialog box of SQL
Server Enterprise Manager.
The following restrictions apply when replicating to an Oracle ODBC
subscriber:
·
The datetime data type is mapped to DATE. The range for the Oracle
DATE data type is between 4712 B.C. and 4712 A.D. If you are replicating to Oracle, verify that
SQL Server datetime entries in a replicated column are within this
range.
· A
replicated table can have only one text or image column.
·
The datetime data type is mapped to the Oracle CHAR data type .
·
The SQL Server ranges for float and real
data types are different from the Oracle ranges.
Drivers for other ODBC subscriber types must conform to the SQL Server
replication requirements for generic ODBC subscribers. The ODBC driver:
·
Must be ODBC Level 1 compliant.
·
Must be 32-bit and thread-safe for the processor architecture that the distribution process
runs on.
·
Must be transaction capable.
·
Must support the data definition language (DDL).
·
Cannot be read-only.
This section presents various methods for migrating data from an Oracle
database to a Microsoft SQL Server database.
The simplest method of migrating between Oracle and SQL Server is to use the
Data Transformation Services (DTS) feature in Microsoft SQL Server 2000. The DTS Import/Export
Wizard guides you through moving the data to SQL Server.
If you have applications that were written by using the Oracle Call Interface
(OCI), you may want to consider rewriting them by using ODBC. The OCI is specific to the Oracle
RDBMS and cannot be used with Microsoft SQL Server or any other database.
In most cases, you can replace OCI functions with the appropriate ODBC
functions, followed by relevant changes to the supporting program code. The remaining non-OCI
program code should require minimal modification. The example shows a comparison of the OCI and
ODBC statements required for establishing a connection to an Oracle database.
|
Oracle Call Interface
|
Oracle ODBC
|
|
rcl = olog(&logon_data_area,
&host_data_area,
user_name, -1, (text*) 0, -1, (text) 0, -1,
OCI_LM_DEF);
|
rcl = SQLConnect(hdbc1,
(SQLCHAR*) ODBC_dsn, (SQLSMALLINT) SQL_NTS,
(SQLCHAR*) user_name, (SQLSMALLINT) SQL_NTS,
(SQLCHAR*) user_password, (SQLSMALLINT) SQL_NTS);
|
The table suggests conversions between Oracle OCI function calls and ODBC
functions. These suggested conversions are approximate. There may not be an exact match in the
conversion process. Your program code might require additional revision to obtain similar
functionality.
|
OCI function
|
ODBC function
|
|
Obindps
|
SQLBindParameter
|
|
Obndra
|
SQLBindParameter
|
|
Obndrn
|
SQLBindParameter
|
|
Obndrv
|
SQLBindParameter
|
|
Obreak
|
SQLCancel
|
|
Ocan
|
SQLCancel, SQLFreeStmt
|
|
Oclose
|
SQLFreeStmt
|
|
Ocof
|
SQLSetConnectOption
|
|
Ocom
|
SQLTransact
|
|
Ocon
|
SQLSetConnectOption
|
|
Odefin
|
SQLBindCol
|
|
Odefinps
|
SQLBindCol
|
|
Odescr
|
SQLDescribeCol
|
|
Oerhms
|
SQLError
|
|
Oexec
|
SQLExecute, SQLExecDirect
|
|
Oexfet
|
SQLExecute, SQLExecDirect, and SQLFetch
|
|
Oexn
|
SQLExecute, SQLExecDirect
|
|
Ofen
|
SQLExtendedFetch
|
|
Ofetch
|
SQLFetch
|
|
Oflng
|
SQLGetData
|
|
Ogetpi
|
SQLGetData
|
|
Olog
|
SQLConnect
|
|
Ologof
|
SQLDisconnect
|
|
Oopen
|
SQLExecute, SQLExecDirect
|
|
Oparse
|
SQLPrepare
|
|
Orol
|
SQLTransact
|
Many applications are written using the Oracle Programmatic Interfaces (Pro*C,
Pro*Cobol, and so on). These interfaces support the use of SQL-92 standard embedded SQL. They
also include nonstandard Oracle programmatic extensions.
Oracle embedded SQL applications can be migrated to SQL Server by using the
Microsoft Embedded SQL (ESQL) for C development environment. This environment provides
adequate, but less than optimal, control over the performance and the use of SQL Server
features compared to an ODBC application.
Some of the Oracle Pro*C features are not supported in Microsoft's ESQL
precompiler. If your Oracle application makes extensive use of these features, a rewrite to
ODBC is probably a better migration choice. These features include:
·
Host array variables.
·
VAR and TYPE statements for data type equivalencing.
·
Support for embedded SQL in Microsoft Visual C++® modules.
·
Support for embedded PL/SQL or Transact‑SQL blocks.
·
Cursor variables.
·
Multithreaded application support.
·
Support for the Oracle Communication Area (ORACA).
If your Oracle application has been developed in Cobol, it can be moved to
Embedded SQL for Cobol from Micro Focus. You may run into some of the same limitations in Cobol
as with the Microsoft ESQL for C precompiler.
You can convert your Oracle embedded SQL application to the ODBC environment.
This migration process is quite easy and offers many advantages. ODBC does not require the use
of a precompiler, as does embedded SQL. Consequently, much of the overhead associated with
program development is eliminated.
The table shows the approximate relationship between Embedded SQL statements
and ODBC functions.
|
Embedded SQL statement
|
ODBC function
|
|
CONNECT
|
SQLConnect
|
|
PREPARE
|
SQLPrepare
|
|
EXECUTE
|
SQLExecute
|
|
DECLARE CURSOR and OPEN CURSOR
|
SQLExecute
|
|
EXECUTE IMMEDIATE
|
SQLExecDirect
|
|
DESCRIBE SELECT LIST
|
SQLNumResultCols, SQLColAttributes,
SQLDescribeCol
|
|
FETCH
|
SQLFetch
|
|
SQLCA.SQLERRD[2]
|
SQLRowCount
|
|
CLOSE
|
SQLFreeStmt
|
|
COMMIT WORK, ROLLBACK WORK
|
SQLTransact
|
|
COMMIT WORK RELEASE,
ROLLBACK WORK RELEASE
|
SQLDisconnect
|
|
SQLCA, SQLSTATE
|
SQLError
|
|
ALTER, CREATE, DROP, GRANT, REVOKE
|
SQLExecute, SQLExecDirect
|
The most significant change, when converting embedded SQL programs to ODBC,
involves the handling of SQL statement errors. The MODE = ORACLE option is often used when
developing embedded SQL programs. When this option is used, the SQL Communications Area (SQLCA)
is typically used for error handling operations.
The SQLCA structure provides:
·
Oracle error codes.
·
Oracle error messages.
·
Warning flags.
·
Information regarding program events.
·
The number of rows processed by the most recent SQL statement.
In most cases, you should check the value in the sqlca.sqlcode variable following the execution of each SQL statement. If the
value is less than zero, an error has occurred. If the value is greater than zero, the
requested statement executed with warnings. The Oracle error message text can be retrieved from
the sqlca.sqlerrm.sqlerrmc variable.
In ODBC, a function returns a numeric status code that indicates its success or
failure following the requested operation. The status codes are defined as string literals, and
include SQL_SUCCESS, SQL_SUCCESS_WITH_INFO, SQL_NEED_DATA, SQL_ERROR, and others. It is your
responsibility to check these return values following each function call.
An associated SQLSTATE value can be obtained by calling the SQLError function. This function returns the SQLSTATE error code, the native
error code (specific to the data source), and the error message text.
An application typically calls this function when a previous call to an ODBC
function returns SQL_ERROR or SQL_SUCCESS_WITH_INFO. However, any ODBC function can post zero
or more errors each time it is called, so an application may call SQLError after every ODBC function call.
Here are examples of error handling for each environment.
|
Oracle Pro*C and EMBEDDED SQL
|
Oracle ODBC
|
|
EXEC SQL DECLARE CURSOR C1 CURSOR
FOR SELECT SSN, FNAME, LNAME FROM STUDENT ORDER BY SSN;
EXEC SQL OPEN C1;
if (sqlca.sqlcode) != 0 {
/* handle error condition,
look at sqlca.sqlerrm.sqlerrmc for error description...*/}
|
if (SQLExecDirect(hstmtl,
(SQLCHAR*)"SELECT SSN, FNAME, LNAME
FROM STUDENT ORDER BY SSN",
SQL_NTS) != SQL_SUCCESS) {
/* handle error condition, use SQLError
for SQLSTATE details regarding error...*/}
|
If you have developed an application using Oracle Developer 2000 and want to
use it with SQL Server, consider converting it to Microsoft Visual Basic®. Visual Basic is a powerful development system that works well
with both databases. You might also consider other development tools in the Microsoft Visual
Studio® development system, or PowerBuilder, SQL
Windows, and others.
If you are unable to immediately migrate from Developer 2000, consider the
Oracle Gateway to SQL Server. It can be used as an intermediate step when migrating from Oracle
to SQL Server. This gateway allows the Oracle RDBMS to connect to SQL Server. All requests for
SQL Server data are automatically translated by the gateway. From the perspective of the
Developer 2000 application, this connection is transparent. SQL Server data appears as Oracle
data. Very few changes need to be made to the application program code.

Another intermediate step is to use the Developer 2000 application directly
with SQL Server. Developer 2000 can directly access SQL Server using the Oracle Open Client
Adapter (OCA). The OCA is ODBC Level 1 compliant and has limited support for ODBC Level 2
functions.
The OCA establishes a connection with the SQL Server ODBC driver. When
connecting the Developer 2000 tools to SQL Server, you must specify an ODBC data source name as
part of the database connection string. When you exit the Developer 2000 application, the OCA
connection to the ODBC data source is disconnected.
The syntax for the logon connect string is demonstrated in the following
example. In this example, the user logs on to the SQL Server STUDENT_ADMIN account. The name of the SQL Server ODBC data source is
STUDENT_DATA:
STUDENT_ADMIN/STUDENT_ADMIN@ODBC:STUDENT_DATA
Using an ODBC driver does not ensure that a Developer 2000 application will
work correctly with SQL Server. The application program code must be modified to work with a
non-Oracle data source. For example, the column security property is Oracle-specific and does
not work with SQL Server.
You must change the key mode that is used to identify each row of data. When
using Oracle as the data source, a ROWID is used to identify each row. When using SQL Server,
you must work with unique primary key values to ensure unique row values.
The locking mode also must be changed. When using Oracle, Developer 2000
attempts to lock a row of data immediately following any change to that row. When using SQL
Server, the locking mode should be set to delayed so that the record is locked only when it is
written to the database.
They are many other issues that must be resolved, including the potential for a
deadlock situation if multiple inserts on a table access the same page of data in a PL/SQL
program block. For more information, see "Transactions, Locking, and Concurrency" earlier in
this paper.
Microsoft SQL Server includes the Web Assistant Wizard, which generates
standard HTML files from SQL Server data. The wizard can configure your Web page so that it is
static, updated periodically, or updated when the data is updated. A wizard walks you through
the process of creating the Web page.
