Global Statistics vs. Histograms with
DBMS_STATS Package
Christoph Gächter, Akadia AG
Information Technology, CH-3672 Oberdiessbach
Updated for Oracle 10.2: 15.09.2007 / Martin Zahn
Overview
Optimisation is the process of choosing the most efficient way to execute a SQL statement. The cost-based optimiser uses statistics to calculate the selectivity of predicates and
to estimate the cost of each execution plan.
You must gather statistics on a regular basis to provide the optimiser with information about schema objects. New statistics should be gathered after a schema object's data or structure are modified in ways that make the previous statistics inaccurate.
The ANALYZE statement
The ANALYZE statement should no more be used to collect optimizer statistics. The COMPUTE and ESTIMATE clauses of ANALYZE statement are supported solely for backward compatibility and may be removed in a future release. The DBMS_STATS package collects a broader, more accurate set of statistics, and gathers statistics more efficiently.
You may continue to use ANALYZE statement to for other purposes not related to optimizer statistics collection:
To use the VALIDATE or LIST CHAINED ROWS clauses
To collect information on free list blocks
More information can be found here.
Gathering Statistics with DBMS_STATS Procedures
Statistics are gathered using the DBMS_STATS package. This PL/SQL package is also used to modify, view, export, import, and delete statistics.
The DBMS_STATS package can gather statistics on table and indexes, and well as individual columns and partitions of tables.
When you generate statistics for a table, column, or index, if the data dictionary already contains statistics for the object, then Oracle updates the existing statistics. The older statistics are saved and can be restored later if necessary.
When statistics are updated for a database object, Oracle invalidates any currently parsed SQL statements that access the object. The next time such a statement executes, the statement is re-parsed and the optimizer automatically chooses a new execution plan based on the new statistics.
Collect Statistics on Table Level
sqlplus scott/tiger
exec dbms_stats.gather_table_stats ( -
ownname => 'SCOTT', -
tabname => 'EMP', -
estimate_percent => dbms_stats.auto_sample_size, -
method_opt => 'for all columns size auto', -
cascade => true, -
degree => 5 -
)
/
PL/SQL procedure successfully completed.
ownname
Schema of table to analyze. tabname
Name of table. estimate_percent
Percentage of rows to estimate (NULL means compute). Use the constant DBMS_STATS.AUTO_SAMPLE_SIZE to have Oracle determine the appropriate sample size for good statistics. This is the default. method_opt
The default is FOR ALL COLUMNS SIZE AUTO. cascade
Gather statistics on the indexes for this table. Index statistics gathering is not parallelized. Using this option is equivalent to running the GATHER_INDEX_STATS Procedure on each of the table's indexes. Use the constant DBMS_STATS.AUTO_CASCADE to have Oracle determine whether index statistics to be collected or not. degree
Degree of parallelism. The default for degree is NULL. All Parameters / Options can be found in the Oracle Manual
Collect Statistics on Schema Level
sqlplus scott/tiger
exec dbms_stats.gather_schema_stats ( -
ownname => 'SCOTT', -
options => 'GATHER', -
estimate_percent => dbms_stats.auto_sample_size, -
method_opt => 'for all columns size auto', -
cascade => true, -
degree => 5 -
)
/
PL/SQL procedure successfully completed.
ownname
Schema to analyze (
NULLmeans current schema).options
gather
Reanalyzes the whole schema gather empty
Only analyzes tables that have no existing statistics gather stale
Only reanalyzes tables with more than 10% modifications (inserts, updates, deletes). gather auto
Reanalyzes objects which currently have no statistics and objects with stale statistics (Using gather auto is like combining gather stale and gather empty.) Note that both gather stale and gather auto require monitoring. If you issue the alter table xxx monitoring command, Oracle tracks changed tables with the dba_tab_modifications view, which allows you to see the exact number of inserts, updates, and deletes tracked since the last analysis of statistics.
estimate_percent
Percentage of rows to estimate (NULL means compute). Use the constant DBMS_STATS.AUTO_SAMPLE_SIZE to have Oracle determine the appropriate sample size for good statistics. This is the default. method_opt
The default is FOR ALL COLUMNS SIZE AUTO. cascade
Gather statistics on the indexes for this table. Index statistics gathering is not parallelized. Using this option is equivalent to running the GATHER_INDEX_STATS Procedure on each of the table's indexes. Use the constant DBMS_STATS.AUTO_CASCADE to have Oracle determine whether index statistics to be collected or not. degree
Degree of parallelism. The default for degree is NULL. All Parameters / Options can be found in the Oracle Manual
Collect Statistics on Other Levels
DBMS_STATS can collect optimizer statistics on the following levels, see Oracle Manual
GATHER_DATABASE_STATS
GATHER_DICTIONARY_STATS
GATHER_FIXED_OBJECTS_STATS
GATHER_INDEX_STATS
GATHER_SCHEMA_STATS
GATHER_SYSTEM_STATS
GATHER_TABLE_STATS
Statistics for Partitioned Schema Objects
Partitioned schema objects may contain multiple sets of statistics. They can have statistics which refer to the entire schema object as a whole (global statistics), they can have statistics which refer to an individual partition, and they can have statistics which refer to an individual sub-partition of a composite partitioned object.
Unless the query predicate narrows the query to a single partition, the optimizer uses the global statistics. Because most queries are not likely to be this restrictive, it is most important to have accurate global statistics. Therefore, actually gathering global statistics with the DBMS_STATS package is highly recommended.
Oracle Histogram Statistics
If DBMS_STATS discovers an index whose columns are unevenly distributed, it will create histograms for that index to aid the cost-based SQL optimizer in making a decision about index versus full-table scan access.
Example
First we set up a table with some very skewed data - so skewed that when we query WHERE ID=1, Oracle Database will want to use an index on ID, and when we query WHERE ID=99, Oracle Database will not want to use an index.
sqlplus scott/tiger
CREATE TABLE skewed_data
AS
SELECT DECODE(ROWNUM,1,1,99) id,
all_objects.*
FROM all_objects
/
Table created.
CREATE INDEX idx_skewed_data ON skewed_data (id);
Index created.
begin
dbms_stats.gather_table_stats
( ownname => USER,
tabname => 'SKEWED_DATA',
method_opt => 'for all indexed columns size 254',
cascade => TRUE
);
end;
/
PL/SQL procedure successfully completed.
set autotrace traceonly explain
SELECT * FROM skewed_data WHERE id=1;
Execution Plan
----------------------------------------------------------
Plan hash value: 1799207757
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 96 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| SKEWED_DATA | 1 | 96 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_SKEWED_DATA | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
SELECT * FROM skewed_data WHERE id=99;
Execution Plan
----------------------------------------------------------
Plan hash value: 746880940
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 51545 | 4832K| 190 (3)| 00:00:03 |
|* 1 | TABLE ACCESS FULL| SKEWED_DATA | 51545 | 4832K| 190 (3)| 00:00:03 |
---------------------------------------------------------------------------------The Table skewed_data contains a column ID, which is very much skewed most of the values are 99, with one record containing a value of 1. After we index and gather statistics on the table (generating histograms on that indexed column, so the optimizer knows that the data is skewed), we can see that the optimizer prefers an index range scan over a full scan when ID=1 is used and vice versa for ID=99.
Use Histograms!
The cost-based optimiser uses data value histograms to get accurate estimates of the distribution of column data. Histograms provide improved selectivity estimates in the presence of data skew, resulting in optimal execution plans with non-uniform data distributions.
Histograms can affect performance and should be used only when they substantially improve query plans. They are useful only when they reflect the current data distribution of a given column. If the data distribution of a column changes frequently, you must re-compute its histogram frequently.
Number of Histograms
The number of Histograms to used is specified with the SIZE parameter in method_opt:
method_opt => 'for all indexed columns size 254',
What are Histograms
Histograms are bands of column values, so that each band contains approximately the same number of rows. The useful information that the histogram provides is where in the range of values the endpoints fall.
Consider the following table column with values between 1 and 100 and a histogram with 10 buckets. If the data in the column is uniformly distributed, then the histogram looks as follows, where the numbers are the endpoint values.
Histogram with Uniform Distribution
The number of rows in each bucket is 1/10 of the total number of rows in the table.
If the data is not uniformly distributed, then the histogram might look as follows:
Histogram with Non-Uniform Distribution
In this case, most of the rows have the value 5 for the column. Only 1/10 of the rows have values between 60 and 100.
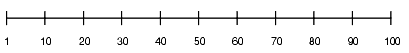
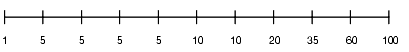
Conclusion
The package DBMS_STATS can be used to gather global statistics. It is most important to have accurate global statistics for partitioned schema objects. Histograms can affect performance and should be used only when they substantially improve query plans.