SQL Server Data Structure
Table Structure
Pages and Extents
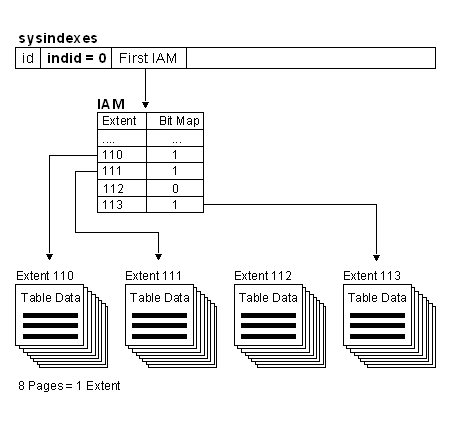
The actual data in your table is stored in Pages, except BLOB data. If a column contain BLOB data then a 16 byte pointer is used to reference the BLOB page. The Page is the smallest unit of data storage in Microsoft SQL Server. A page contains the data in the rows. A row can only reside in one page. Each Page can contain 8KB of information, due to this, the maximum size of a Row is 8KB. A group of 8 adjacent pages is called an extent. A heap is a collection of data pages.
Heaps and the Index Allocation Map (IAM)
Heaps have one row in sysindexes with indid = 0. The column sysindexes.FirstIAM points to the first IAM page in the chain of IAM pages that manage the space allocated to the heap. Microsoft® SQL Server™ 2000 uses the IAM (Index Allocation Map) pages to navigate through the heap. The data pages and the rows within them are not in any specific order, and are not linked together. The only logical connection between data pages is that recorded in the IAM pages.
Index Structure
All SQL Server indexes are B-Trees. There is a single root page at the top of the tree, branching out into N number of pages at each intermediate level until it reaches the bottom, or leaf level, of the index. The index tree is traversed by following pointers from the upper-level pages down through the lower-level pages. In addition, each index level is a separate page chain.There may be many intermediate levels in an index. The number of levels is dependent on the index key width, the type of index, and the number of rows and/or pages in the table. The number of levels is important in relation to index performance.
Nonclustered Indexes
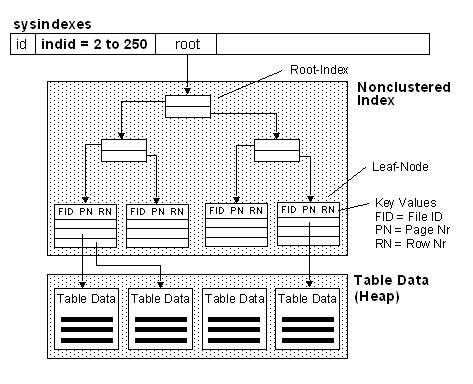
A nonclustered index is analogous to an index in a textbook. The data is stored in one place, the index in another, with pointers to the storage location of the data. The items in the index are stored in the order of the index key values, but the information in the table is stored in a different order (which can be dictated by a clustered index). If no clustered index is created on the table, the rows are not guaranteed to be in any particular order.
Similar to the way you use an index in a book, Microsoft® SQL Server™ 2000 searches for a data value by searching the nonclustered index to find the location of the data value in the table and then retrieves the data directly from that location. This makes nonclustered indexes the optimal choice for exact match queries because the index contains entries describing the exact location in the table of the data values being searched for in the queries. If the underlying table is sorted using a clustered index, the location is the clustering key value; otherwise, the location is the row ID (RID) comprised of the file number, page number, and slot number of the row. For example, to search for an employee ID (emp_id) in a table that has a nonclustered index on the emp_id column, SQL Server looks through the index to find an entry that lists the exact page and row in the table where the matching emp_id can be found, and then goes directly to that page and row.
Considerations
Consider using nonclustered indexes for:
- Columns that contain a large number of distinct values, such as a combination of last name and first name (if a clustered index is used for other columns). If there are very few distinct values, such as only 1 and 0, most queries will not use the index because a table scan is usually more efficient.
- Queries that do not return large result sets.
- Columns frequently involved in search conditions of a query (WHERE clause) that return exact matches.
- Decision-support-system applications for which joins and grouping are frequently required. Create multiple nonclustered indexes on columns involved in join and grouping operations, and a clustered index on any foreign key columns.
- Covering all columns from one table in a given query. This eliminates accessing the table or clustered index altogether.
Clustered Indexes
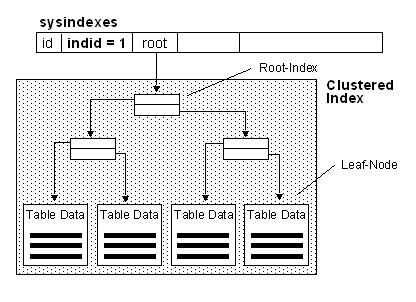
A clustered index determines the physical order of data in a table. A clustered index is analogous to a telephone directory, which arranges data by last name. Because the clustered index dictates the physical storage order of the data in the table, a table can contain only one clustered index. However, the index can comprise multiple columns (a composite index), like the way a telephone directory is organized by last name and first name. Clustered Indexes are very similar to Oracle's IOT's (Index-Organized Tables).
A clustered index is particularly efficient on columns that are often searched for ranges of values. After the row with the first value is found using the clustered index, rows with subsequent indexed values are guaranteed to be physically adjacent. For example, if an application frequently executes a query to retrieve records between a range of dates, a clustered index can quickly locate the row containing the beginning date, and then retrieve all adjacent rows in the table until the last date is reached. This can help increase the performance of this type of query. Also, if there is a column(s) that is used frequently to sort the data retrieved from a table, it can be advantageous to cluster (physically sort) the table on that column(s) to save the cost of a sort each time the column(s) is queried.
Clustered indexes are also efficient for finding a specific row when the indexed value is unique. For example, the fastest way to find a particular employee using the unique employee ID column emp_id is to create a clustered index or PRIMARY KEY constraint on the emp_id column.
Note PRIMARY KEY constraints create clustered indexes automatically if no clustered index already exists on the table and a nonclustered index is not specified when you create the PRIMARY KEY constraint.
Considerations
It is important to define the clustered index key with as few columns as possible. If a large clustered index key is defined, any nonclustered indexes that are defined on the same table will be significantly larger because the nonclustered index entries contain the clustering key.
Consider using a clustered index for:
- Columns that contain a large number of distinct values.
- Queries that return a range of values using operators such as BETWEEN, >, >=, <, and <=.
- Columns that are accessed sequentially.
- Queries that return large result sets.
- Columns that are frequently accessed by queries involving join or GROUP BY clauses; typically these are foreign key columns. An index on the column(s) specified in the ORDER BY or GROUP BY clause eliminates the need for SQL Server to sort the data because the rows are already sorted. This improves query performance.
- OLTP-type applications where very fast single row lookup is required, typically by means of the primary key. Create a clustered index on the primary key.
Clustered indexes are not a good choice for:
- Columns that undergo frequent changes
This results in the entire row moving (because SQL Server must keep the data values of a row in physical order). This is an important consideration in high-volume transaction processing systems where data tends to be volatile.
- Wide keys
The key values from the clustered index are used by all nonclustered indexes as lookup keys and therefore are stored in each nonclustered index leaf entry.